Entre patrones y pensamiento: qué pueden (y no pueden) hacer los LLM
Por Eduardo Pinto, docente de medicina, miembro de AIpocrates.
Figura 1. Resumen gráfico del debate sobre razonamiento en LLM. Generada por NotebookLM
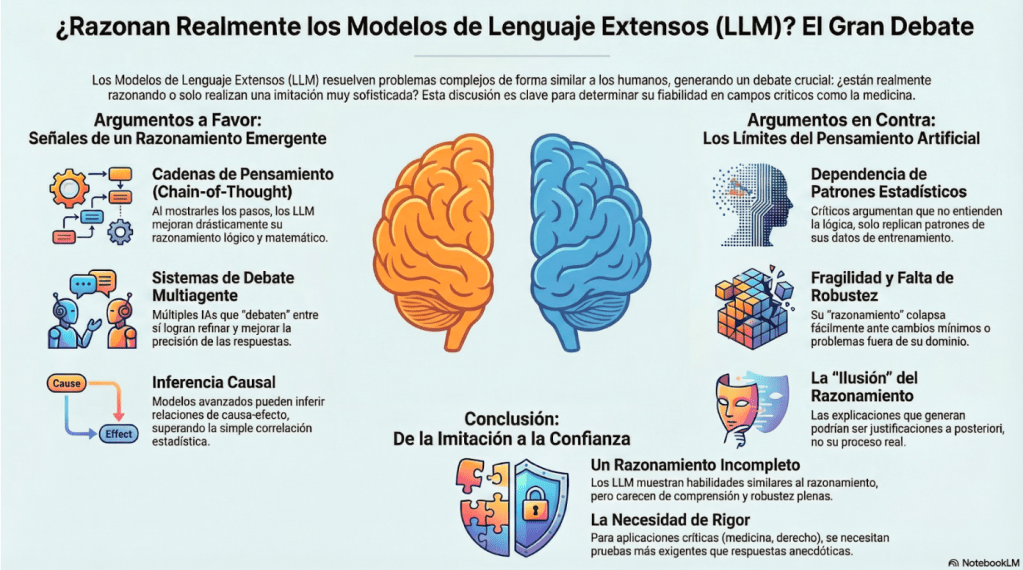
El 26 de julio de 2022 en una columna de Alejandro Hernández, titulada Conversación sobre salud e inteligencia artificial con GPT Neox 20 B un modelo de lenguaje autoregresivo de código abierto basado en Transformers (8), dónde se interactuó con un modelo de inteligencia artificial enfocado en el procesamiento de lenguaje natural. Luego, en noviembre del 2022 se lanzó ChatGPT 3.5, rompiendo los paradigmas, uno de ellos, que por primera vez una máquina superó el Test de Turín.
Desde entonces, con el lanzamiento de cada nuevo modelo, los LLM han sorprendido por su capacidad progresiva para resolver problemas que antes se consideraban exclusivos del razonamiento humano, como explicar pasos, corregir errores o planear tareas. Este fenómeno ha generado tanto entusiasmo como inquietud. Estas capacidades han puesto sobre la mesa una pregunta clave: ¿realmente razonan o solo imitan el razonamiento?
En un club de revistas en el canal de YouTube de AIpocrates “Nuevo vértigo de la IA” (8), se muestra cómo comenzaron a aparecer en los modelos tipo LLM una serie de comportamientos no esperados ni programados, conocidos como “comportamientos emergentes”.
El debate sobre la cognición en la IA y la atribución de sentido no es nuevo, pero el éxito de las redes neuronales profundas (DNN) reaviva una pregunta incómoda: ¿si un sistema se comporta como si razonara, razona?
Responder afirmativa o negativamente de forma tajante es tentador, pero conceptualmente pobre. Cuando alguien afirma que:
- Un LLM “razona”, esa afirmación puede significar cosas muy distintas dependiendo de qué entendamos por razonamiento, cómo lo evaluamos y qué evidencia estemos dispuestos a aceptar.
- Un LLM “no razona” tan solo ordena las palabras según la palabra o abolidas “sin pensar”, puede caer en un reduccionismo.
El objetivo de esta columna no es cerrar el debate, sino abrir la discusión para profundizar en el tema, facilitar un análisis más riguroso y el planteamiento de preguntas más precisas en búsqueda de mejores respuestas. La intención es clarificar conceptos, revisar la evidencia disponible, para buscar criterios más sólidos que permitan evaluar, si los LLM realmente razonan o no hoy.
¿Razonan los Modelos de Lenguaje Extensos (LLM)?
No hay, hasta ahora, un consenso técnico plenamente establecido al respecto, pero sí hay trabajos recientes y líneas de debate bastante rigurosas que vale la pena conocer. Algunos adoptan posiciones optimistas y sostienen: “los LLM pueden razonar, al menos hasta cierto punto” y otros más escépticos sostienen “lo que hacen los LLM es manipular patrones estadísticos, no razonar”.
Para evitar confusiones y elevar la calidad de la discusión tanto técnica como pública, es necesario definir:
- Los conceptos relevantes.
- Las preguntas críticas.
- Los argumentos a favor y en contra.
- La evidencia concreta que debe exigirse para sustentar el razonamiento.
Conceptos relevantes
¿Qué entendemos por “razonar”?
Para determinar si los LLM razonan, es necesario precisar primero qué se entiende por razonamiento. Este se define como la capacidad de llegar a conclusiones o resolver problemas de manera lógica y ordenada a partir de información, premisas o evidencias (1). Implica un proceso de conexión de ideas que permite comprender, explicar o tomar decisiones, tradicionalmente asociado a la cognición humana.
Los mecanismos cognitivos básicos son procesos fundamentales que sustentan la cognición y permiten funciones más complejas. Incluyen la percepción, la atención y la memoria, que posibilitan captar, seleccionar y almacenar información; la asociación y la generalización, que conectan experiencias y extraen regularidades; la predicción y el aprendizaje, que anticipan y ajustan el comportamiento; y el control ejecutivo, que coordina y regula estos procesos. En conjunto, constituyen el sustrato sobre el que puede emerger el razonamiento, aunque no lo garantizan por sí mismos.
¿Cuáles son los criterios para decir que se razona?
Razonar implica cumplir ciertos criterios básicos:
• Coherencia lógica: las ideas siguen una secuencia ordenada y no se contradicen.
• Fundamentación: se apoyan en evidencias, principios o experiencias previas.
• Flexibilidad cognitiva: se consideran alternativas y se ajusta el pensamiento ante nueva información.
• Finalidad: se orienta a resolver un problema, tomar una decisión o explicar un fenómeno.
• Conciencia metacognitiva: el sujeto reconoce y evalúa sus propios pasos de pensamiento.
No es necesario cumplir todos los criterios; sin embargo, mientras más se satisfagan, más sólida será la afirmación de que existe razonamiento.
¿Cuáles son los tipos de razonamiento?
Aclarado qué entendemos por razonamiento y para seguir discutiendo si los modelos de lenguaje (LLM) realmente razonan, es necesario entender los distintos modos de razonamiento evitando ambigüedades y generalizaciones apresuradas. Conocer las capacidades cognitivas complejas permite evaluar si los LLM las exhiben o solo reproducen patrones aprendidos.
Conviene aclarar qué hablamos de inferencia como el proceso general mediante el cual se obtienen conclusiones a partir de datos, premisas u observaciones. Puede ser deductiva, inductiva o abductiva, y no implica necesariamente una relación causal real. Causalidad, en cambio, es un tipo particular de inferencia: establece relaciones de causa–efecto y exige criterios más fuertes, como intervenciones, análisis contrafactuales y mecanismos. En otras palabras, toda explicación causal implica inferencia, pero no toda inferencia revela causalidad.
Para ordenar la discusión, es útil distinguir distintos tipos de razonamiento:
- Razonamiento deductivo: Parte de premisas generales para llegar a conclusiones específicas. Si las premisas son verdaderas y la forma lógica es válida, la conclusión lo es necesariamente.
- Razonamiento inductivo: Generaliza a partir de ejemplos u observaciones particulares. Es central en el aprendizaje automático, donde se usa para reconocer patrones y hacer predicciones, aunque sus conclusiones son probabilísticas.
- Razonamiento abductivo: Busca la explicación más plausible para un conjunto de observaciones. Se usa con frecuencia en diagnósticos y formulación de hipótesis.
- Razonamiento de sentido común: Aplica conocimiento cotidiano del mundo para inferir conclusiones razonables, incluyendo suposiciones implícitas, atribución de intenciones y escenarios contrafactuales simples.
- Metarazonamiento: Consiste en reflexionar sobre el propio proceso de razonamiento, detectar errores y corregir inferencias.
- Razonamiento probabilístico o bayesiano: Actualiza creencias bajo incertidumbre a partir de nueva evidencia.
- Razonamiento contrafactual: Evalúa escenarios hipotéticos (“qué habría pasado si…”).
- Razonamiento analógico: Transfiere conocimiento entre dominios similares.
- Razonamiento normativo: Evalúa acciones según reglas, valores o normas.
- Razonamiento práctico o instrumental: Selecciona medios para alcanzar fines.
El deductivo, inductivo y abductivo en lo esencial distinguen adecuadamente certeza vs. plausibilidad/probabilidad.
Razonamiento en LLM
Los LLM, como GPT, PaLM y LLaMA, utilizan arquitecturas tipo “Deep Learning” (DL), redes neuronales tipo transformadores, para procesar y generar texto de tipo humano.
- Los LLM aprenden patrones probabilísticos en datos del lenguaje, lo que da lugar a inferencias implícitas basadas en correlaciones estadísticas y no explícitamente estructurado.
- Habilidad inferencial emergentes: El escalamiento de los LLM incrementa su desempeño en tareas que requieren múltiples pasos intermedios o secuencias.
- Procesamiento contextual guiada por instrucciones: Los LLM dependen en gran medida de la ventana de contexto y de técnicas de prompting (p. ej., chain-of-thought [CoT]) para hacer explícitos los pasos intermedios del proceso computacional (cálculos y estimaciones) como se generó la respuesta.
No existe un consenso universal sobre si los LLM «razonan» o no. Sólo hay acuerdos parciales en indicadores que sugieren un posible razonamiento.
Encuestas recientes intentan establecer taxonomías, criterios de evaluación y categorizaciones, no dictan una definición final. Por ejemplo:
- Presentar una taxonomía del “razonamiento en LLM” que combine regímenes de uso y arquitecturas del modelo, como herramienta para organizar los debates. (2)
- Evaluar el comportamiento de razonamiento implica ir más allá de la mera precisión y reconocer que su evaluación debe abordarse desde múltiples dimensiones. (3)
- Interpretabilidad mecánica: para atribuir comportamiento inferencial confiable a un modelo, se requiere transparencia y explicabilidad de sus mecanismos internos. (4).
Investigadores escépticos, como Yann LeCun, han expresado que los LLM no alcanzarán el razonamiento humano profundo. (5)
Así pues, más que un consenso rígido, existen criterios (robustez, modularidad, explicabilidad, generalización fuera del dominio) bajo los cuales un modelo podría pasar de “imitador potente de razonamiento” a “modelo que podemos calificar como razonador” (al menos en ciertos dominios).
Preguntas críticas
Figura 2 – Preguntas críticas sobre el razonamiento en los Modelos de Lenguaje Extensos
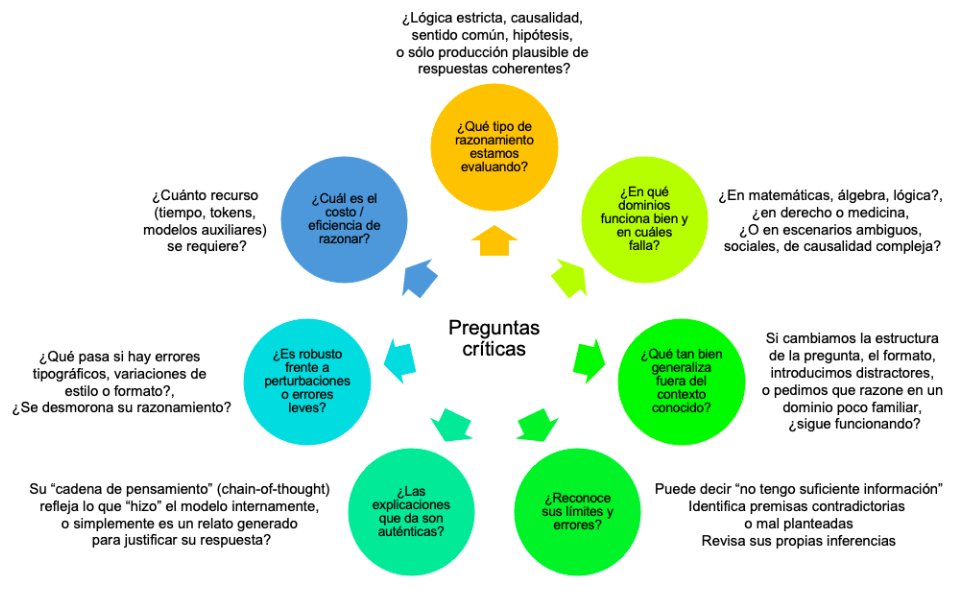
Las siguientes preguntas sirven para orientar adecuadamente la discusión. Es casi seguro que las respuestas obtenidas lo alejen de cualquier extremo radical.
Evidencias concretas:
¿Razonan los LLM actuales?
A favor de que los LLM pueden razonar (o al menos emular razonamiento)
- Emergencia de cadenas de pensamiento (chain-of-thought) y prompting que evoca razonamiento
- LLM pueden razonar mejor de lo que parecía al principio, siempre que se les “guíe” de formas específicas. Al incluir ejemplos con pasos intermedios (CoT) dentro del prompt, los LLMs mejoran sustancialmente en tareas de tareas de lógica, álgebra, puzzles; ganando precisión sin necesidad de reentrenamiento extenso (6, 7).
- No basta con modelos grandes; el diseño del prompt, el razonamiento intermedio y la integración simbólica son claves para desbloquear comportamientos de razonamiento más sofisticados.
- Recientes estudios muestran que las mejoras en prompting avanzado, diseño modular de tareas y aprendizaje contextual efectivamente elevan el rendimiento de los LLMs en tareas de múltiples pasos (8). Técnicas como: self-reflection, heuristic mutation y planning prompting permiten cerrar la brecha de desempeño entre modelos grandes y pequeños, especialmente en entornos dinámicos. (8)
Mejora mediante verificación iterativa / uso de módulos auxiliares
- Algunos estudios emplean estrategias donde el modelo genera razonamientos candidatos y un módulo verificador los evalúa o corrige, fortaleciendo la consistencia.
- Esta arquitectura modular es más prometedora que la generación pura. (9)
Sistemas multiagente / debate entre instancias
- Una línea creciente es la de hacer que múltiples instancias del modelo “debatan” posibles razonamientos entre sí, de modo que emergen mejores respuestas (por intercambio crítico).
- Por ejemplo, Du et al. (2023) muestra que este enfoque mejora la exactitud en tareas de razonamiento. (10)
- También (11) extiende esto a debates estructurados sobre textos científicos. Otro es SocraSynth que utiliza razonamiento dialéctico entre agentes para robustecer argumentos. (12)
Razonamiento lingüístico
- Mediante pruebas lingüísticas con una lengua inventada, se evaluó la capacidad de razonamiento humano de los LLM.
- El modelo (o1) mostró una habilidad metalingüística superior, lo que implica que no solo usa el lenguaje, sino que también reflexiona sobre él (13).
Razonamiento causal
- Estudios recientes indican que modelos avanzados como GPT-4o pueden realizar inferencias causales comparables o mejores que las humanas en ciertos dominios, sugiriendo que internalizan estructuras causales y no sólo correlaciones superficiales (14).
Razonamiento reforzado / modelos especiales de razonamiento
- Se han propuesto los Large Reasoning Models (LRMs), estructurados o entrenados para razonar explícitamente (ej. generando trazas de pensamiento) (15).
- No obstante, que un modelo genere «trazas» no prueba que sean las operaciones internas reales, pudiendo ser una narrativa justificatoria post-hoc.
Capacidades composicionales emergentes
- Un factor clave del razonamiento humano es la capacidad de componer conceptos nuevos de partes conocidas.
- Russin et al. estudian si los modelos pueden exhibir generalización composicional (por ejemplo, entendiendo expresiones nuevas combinando partes conocidas).
- Observan que en algunos casos los LLMs sí logran comportamientos composicionales convincentes, lo cual fortalece la hipótesis de que no todo su “pensar” es mera memorización de ejemplos vistos. (16)
Así pues, los LLMs demuestran capacidades de razonamiento emergentes (o potente imitación) en condiciones óptimas, mejorables con arquitecturas auxiliares (verificadores, debates, agentes). Sin embargo, no hay consenso de que razonen igual que los humanos o en todos los casos.
Críticas, escepticismo, evidencias y argumentos en contra
Dependencia de patrones estadísticos / correlaciones superficiales
- Se critica que los modelos aprenden y extienden correlaciones estadísticas de los datos de entrenamiento, sin inferir estructuras lógicas profundas.
- Al revisar estudios, Mondorf & Plank concluyen que los LLM “tienden a apoyarse en patrones superficiales y correlaciones” más que en razonamiento sofisticado. (2) Críticas recientes advierten que CoT fallan bajo desviaciones ligeras de dominio. (17)
La ilusión del pensamiento / trazas no confiables
- Que un modelo reporte una CoT no refleja necesariamente su proceso interno; podría ser una justificación a posteriori.
- Un artículo crítico reciente discute esta “ilusión del razonamiento” en el contexto de los LLMs y cuestiona hasta qué punto las trazas justificatorias son fiables. (18)
- Sin embargo, hay una réplica (19) que defiende algunos usos de trazas, argumentando que los fallos observados dependen del diseño experimental.
Falta de robustez / generalización frágil
- Un fuerte argumento contra el razonamiento pleno de los LLM es que, a pesar de su buen rendimiento en ciertos benchmarks, sus inferencias fallan fácilmente ante perturbaciones leves, ejemplos adversariales o fuera de su dominio de entrenamiento (17, 20, 21, 22, 31).
- Esa falta de robustez sugiere que no hay un razonamiento profundo subyacente con base firme.
Inexplicabilidad interna / caja negra
- Para que un modelo razone profundamente, se esperaría que su estructura interna revelara operaciones lógicas.
- Aunque se sabía que los modelos podían estimar su conocimiento y reconocer resultados, las activaciones internas en tareas introspectivas no se habían investigado; pero el grupo de Anthropic ha demostrado que los LLM modernos tienen una forma limitada de conciencia introspectiva, respondiendo con precisión sobre sus estados internos aunque en una proporción limitada y bajo condiciones especiales (23).
Razonamiento fluido
- En un reciente marco de evaluación de la Inteligencia General Artificial (AGI): el razonamiento In Situ (R) se definió como el control deliberado pero flexible de la atención para solucionar problemas novedosos que no pueden resolverse utilizando únicamente hábitos, esquemas o guiones previamente aprendidos.
- El dominio R se desglosa en cinco sub-habilidades: Deducción, Inducción, Teoría de la Mente, Planificación y Adaptación. GPT-4 (2023) demostró capacidades de R insignificantes (0%), mientras que GPT-5 (2025) mostró una mejora sustancial al alcanzar un 7% del 10% total del dominio R; este modelo alcanzó la máxima puntuación en deducción (2%), teoría de la mente (2%) y planificación (1%), logró la mitad de la puntuación en inducción (2% de 4%), pero mostró una capacidad nula en adaptación (0%). (24)
Argumentos filosóficos clásicos: simbolismo vs. conexión, grounding y sentido. Desde la filosofía de la mente y de la IA, hay argumentos históricos relevantes:
- El grounding (vínculo entre símbolos y mundo real) es un obstáculo clave para atribuir razonamiento a sistemas que solo manipulan representaciones arbitrarias (25). La crítica al conexionismo señala que, sin estructuras simbólicas explícitas y variables, los modelos neuronales no pueden explicar la lógica humana (26).
- Desde la filosofía de la cognición, el computacionalismo fuerte (cognición como cálculo simbólico) ha sido cuestionado, argumentándose que la cognición humana requiere heurísticas, contexto y experiencia corporal, dimensiones que los modelos actuales no capturan. Ante esto, surgen los modelos neuro-simbólicos, que integran mecanismos conexionistas y estructuras simbólicas para abordar tareas de razonamiento complejo (27).
- Sin embargo, los LLM, aunque exhiben una fluidez superficial notable, suelen fallar en tareas que requieren razonamiento simbólico, precisión aritmética o consistencia lógica. Con frecuencia, articulan principios correctos sin aplicarlos de manera fiable, fenómeno descrito como “síndrome de cerebro computacional dividido” (28).
- Más recientemente, algunos trabajos filosóficos han discutido cómo los modelos contemporáneos desafían las concepciones clásicas de representación y comprensión, reabriendo el debate sobre qué significa realmente “entender” en un sistema artificial (29).
Argumentos radicales: “razonar” es solo metáfora
- Críticos sostienen que atribuir «razonamiento» a los LLM es una metáfora engañosa. Argumentan que los LLM solo predicen la distribución de tokens según el contexto, sin verdadera inferencia, por lo que carecen de «creencias», «representaciones lógicas» o «intenciones» reales, aunque sus resultados simulen el razonamiento humano. Esta postura escéptica radical es común entre los críticos filosóficos.
Para resumir, los argumentos en contra son que los LLM se apoyan en correlaciones estadísticas, son vulnerables ante perturbaciones, las DNN son opacas, su capacidad aún no alcanza la de un adulto bien educado y argumentos filosóficos que sugieren que los LLM aún no razonan plenamente y que su “razorar” es apenas metafórico.
Evidencias pertinentes
Para sostener una afirmación de razonamiento, no basta con mostrar una buena salida a un prompt exitoso. Aquí hay algunos ejemplos recientes de evidencia pertinente:
| Tipo de evidencia | Qué pone a prueba | Ejemplo |
|---|---|---|
| Generalización fuerte | Que el modelo resuelva problemas nuevos, no sólo variantes del entrenamiento | ARC Benchmark muestra mejoras al añadir conocimiento explícito (30) |
| Representaciones tipo creencia | Que existan estados internos estables que guíen las inferencias | Criterios de belief-like representations propuestos por Herrmann & Levinstein (31) |
| Robustez a perturbaciones | Que el razonamiento no colapse ante cambios mínimos | Errores tipográficos reducen drásticamente el desempeño en GSM8K (32) |
| Variaciones numéricas / estructurales | Que apliquen reglas y abstraiga, no que memorice patrones | Fallos frecuentes ante cambios numéricos en tareas matemáticas (33) |
| Dominios aplicados sensibles | Que razone de forma fiable donde los errores importan | Knowledge-injection attacks en tareas legales revelan fragilidad lógica (34) |
Conclusión
Algunos LLM muestran capacidades tipo razonamiento en dominios estructurados, pero aún falta evidencia de que «razonan plenamente» con comprensión, creencias internas estables, robustez y control flexible ante situaciones nuevas.
Parte del problema es que muchas de las exigencias a los LLM son antropocéntricas: juzgamos su desempeño comparándolos con los humanos. Sin embargo, los sistemas de IA que superan a las personas en tareas complejas desafían esta comparación. Tal vez la pregunta es ¿qué tipo de razonamiento estamos dispuestos a aceptar como suficiente en contextos críticos?
El asunto no es meramente filosófico. En medicina, derecho o finanzas, confiar en un sistema que “parece razonar” sin comprender sus límites puede tener consecuencias graves. Por ello, más que proclamar victorias conceptuales, necesitamos marcos de evaluación más rigurosos, evidencia menos anecdótica y una discusión honesta sobre cuándo un modelo deja de ser un imitador sofisticado y pasa a ser una herramienta confiable para apoyar decisiones humanas.
La pregunta, entonces, queda abierta: ¿qué tendría que demostrar un modelo para que estemos dispuestos a decir, sin comillas, que razona? Y, quizás más importante aún, ¿qué nivel de razonamiento exigimos antes de permitirle influir en decisiones clínicas reales?
Declaración de uso de IA
El autor declara haber utilizado Chat GPT y Notebook LM para revisar literatura, optimizar redacción y generar imágenes. El autor se hace responsable del contenido.
Referencias bibliográficas
https://docs.google.com/document/d/1t4AjyAPdX3mZPVn6VV8oV6bvP3U–LuDDnufXDZnRCM/edit?usp=sharing
