Por: Luis Eduardo Pinto, MD, miembro de AIpocrates
Esta semana, gracias a una gentil invitación de la Asociación Colombiana de Medicina del Sueño (ACMES) a su III Master Class Insomnio y Somnolencia diurna excesiva, en cabeza de nuestra compañera de AIpocrates Leslie Vargas, tuvimos la oportunidad de compartir nuestra perspectiva acerca de ¿cómo podemos leer, entender y, sobre todo, evaluar críticamente la inteligencia artificial (IA) en medicina del sueño.
La medicina del sueño es una disciplina que, por su naturaleza, se encuentra en una encrucijada perfecta para la innovación a través de la IA. El diagnóstico de los trastornos del sueño, como el insomnio o la apnea, depende en gran medida del análisis de estudios de polisomnografía (PSG). Estos estudios registran múltiples variables fisiológicas durante la noche: la actividad eléctrica del cerebro (electroencefalograma o EEG), el movimiento de los ojos (electrooculograma o EOG), el tono muscular (electromiograma o EMG), el flujo de aire, el esfuerzo respiratorio, la oxigenación de la sangre y más. El resultado es un vasto océano de datos, una representación gráfica de las complejidades del sueño que un experto humano debe navegar manualmente, segundo a segundo, para clasificar las diferentes etapas del sueño y detectar eventos anormales. [1]
Esta tarea, conocida como «puntuación» del sueño, es laboriosa, consume tiempo y es susceptible a la variabilidad entre los expertos. Dos somnólogos, ambos altamente capacitados, pueden interpretar el mismo registro de sueño con pequeñas, pero a veces significativas, diferencias. Es aquí donde la IA entra en escena.
El lenguaje del sueño: De las señales a las representaciones
Para que una máquina pueda «leer» un estudio de sueño, primero debemos traducir el lenguaje de la fisiología a un formato que pueda procesar. Las señales de un PSG son, en esencia, series de tiempo: mediciones de voltaje que cambian segundo a segundo. La IA, y en particular las redes neuronales profundas (un subcampo del machine learning), necesitan que estos datos crudos se transformen en «representaciones» significativas.
Imaginen que intentan entender una conversación en un idioma desconocido. Al principio, solo oyen una corriente de sonidos. Pero si alguien les muestra cómo esos sonidos se agrupan para formar palabras y cómo esas palabras se combinan para crear frases, comienzan a percibir una estructura. De manera análoga, para analizar el sueño, no solo miramos la señal de EEG como una línea ondulada; buscamos patrones específicos. [1] Durante las diferentes etapas del sueño, nuestro cerebro produce distintas «ondas» con frecuencias características: las oscilaciones lentas y profundas del sueño de ondas lentas (etapa N3), los «husos de sueño» y los «complejos K» de la etapa N2, y las ondas theta del sueño REM, entre otras (Figura 1). [1]

Figura 1. Arquitectura del sueño como hipnograma (A). Formas ondulatorias características (B). Imagen tomada de: Klinzing, Jens G et al. Nature neuroscience vol. 22,10 (2019).
La IA aprende a reconocer estas representaciones. Una de las técnicas más poderosas para lograr esto es la transformación de las señales de EEG en espectrogramas. Un espectrograma es una representación visual de la frecuencia de una señal a lo largo del tiempo. [4,6] Piensen en ello como la partitura de una pieza musical, donde en lugar de notas, tenemos las diferentes frecuencias de las ondas cerebrales, y su «volumen» o potencia se representa con colores (Figura 2). De repente, la señal de EEG, que era una línea compleja, se convierte en una imagen rica en patrones. Una red neuronal convolucional (CNN), un tipo de algoritmo de IA inspirado en la corteza visual humana, es excepcionalmente buena para «ver» y aprender de imágenes. [2,8] Así, una CNN puede aprender a identificar las características visuales de un espectrograma que corresponden a una etapa específica del sueño, de la misma manera que aprendería a diferenciar la foto de un gato de la de un perro.
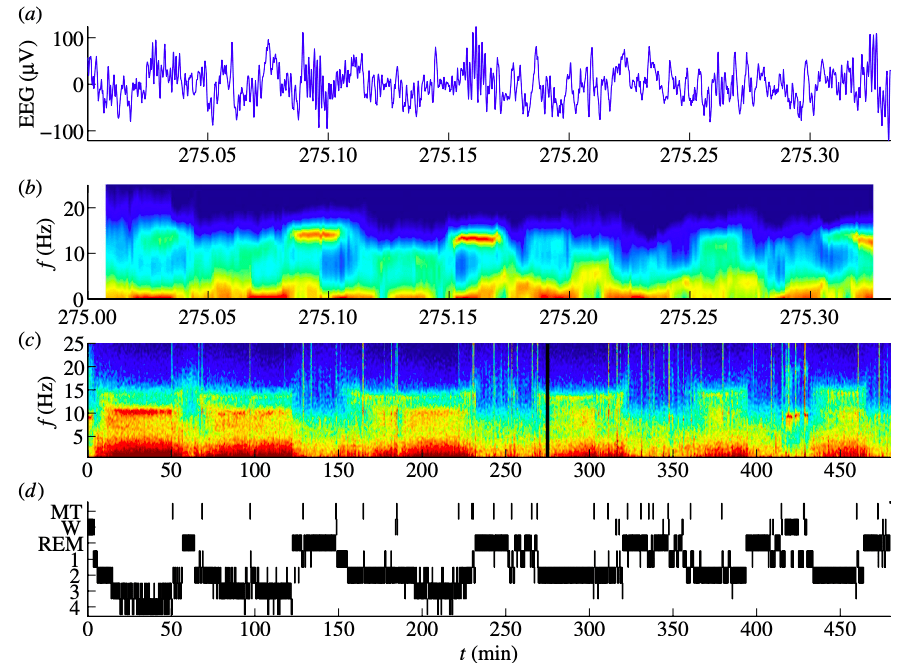
Figura 2.Representaciones del sueño. a) Época de 20 segundos de datos de EEG. Espectrogramas codificados por colores en segmentos de b) 1 segundo y de c) 20 segundos y d) Hipnograma. Imagen tomada de: Olbrich, Eckehard et al. Philosophical transactions. vol. 369,1952 (2011): 3884-901.
Las 5 fases del aprendizaje automático del sueño
Para que este proceso de aprendizaje ocurra de manera estructurada y científicamente rigurosa, seguimos una serie de pasos que son fundamentales en cualquier estudio de machine learning clínico. Inspirados en la lista de verificación MI-CLAIM (Información Mínima sobre el Modelado de Inteligencia Artificial Clínica), podemos desglosar este proceso en cinco fases clave.[3]
- Etiquetado por expertos humanos: Antes de que la máquina pueda aprender, alguien tiene que enseñarle. En el caso de la medicina del sueño, los somnólogos revisan cientos o miles de estudios de PSG y «etiquetan» cada época de 30 segundos con la etapa de sueño correspondiente (Vigilia, N1, N2, N3 o REM). Este conjunto de datos etiquetado es el «libro de texto» a partir del cual aprenderá el algoritmo.
- Pre-procesamiento y extracción de características: Los datos crudos del PSG se limpian y transforman. Esto implica filtrar el «ruido» (interferencias) y, como mencionamos, convertir las señales en representaciones útiles como los espectrogramas. Este paso es crucial para asegurar que la IA se enfoque en la información fisiológica relevante.
- Entrenamiento y validación: El conjunto de datos etiquetado se divide. Una gran parte (generalmente alrededor del 80%) se utiliza para «entrenar» el modelo. El algoritmo procesa estos datos, intenta predecir la etapa del sueño para cada época y compara su predicción con la etiqueta del experto. Si se equivoca, ajusta sus parámetros internos para hacerlo mejor la próxima vez. Este proceso se repite muchas veces. Una porción más pequeña de los datos, el «conjunto de validación», se utiliza para ajustar los «hiperparámetros» del modelo – decisiones de diseño sobre la arquitectura de la red – y para monitorear el aprendizaje, asegurando que el modelo no esté simplemente «memorizando» los datos de entrenamiento, un problema conocido como sobreajuste o overfitting, que amenaza la capacidad del modelo de poder generalizar a conjuntos de datos independientes. [8,10]
- Prueba con datos independientes: Una vez que el modelo está entrenado y validado, su rendimiento real se evalúa en un «conjunto de prueba». Estos son datos que el modelo nunca ha visto antes. Es el examen final. Esto nos dice qué tan bien el modelo «generaliza» su conocimiento a nuevos «pacientes».
- Medición del desempeño: Finalmente, medimos qué tan bien lo hizo el modelo. No basta con decir que fue «preciso». Necesitamos métricas específicas que nos den una visión matizada de su rendimiento [11].
Para ilustrar este proceso, echemos un vistazo a un estudio real: «Validation Study on Automated Sleep Stage Scoring Using a Deep Learning Algorithm» de Cho et al. (2022). [5] En este trabajo, los investigadores se propusieron verificar la precisión de un algoritmo de aprendizaje profundo (llamado StageNet) para la clasificación automática de las etapas del sueño en comparación con la calificación manual.
Los datos provinieron de 602 estudios de polisomnografía del Hospital de la Universidad de Soonchunhyang en Corea del Sur. Siguiendo el proceso que describimos, los datos fueron etiquetados por expertos siguiendo las directrices de la Academia Americana de Medicina del Sueño (AASM). Luego, el conjunto de datos se dividió: 482 estudios para entrenamiento, 48 para validación y 72 para la prueba final (Figura 3). [4]

Figura 3.División del conjunto de datos de PSG para desarrollar el modelo StageNet. [5]
Abriendo la «Caja Negra»: ¿Cómo Aprende la Máquina?
El corazón de este tipo de estudios es el modelo de IA en sí. A menudo, las redes neuronales profundas son descritas como «cajas negras», lo que significa que pueden ser increíblemente buenas para hacer predicciones, pero es difícil entender exactamente cómo llegan a sus conclusiones. [9] Sin embargo, podemos desmitificar parte del proceso.
En el caso de un modelo que utiliza espectrogramas, la CNN funciona de manera jerárquica. [6] Las primeras capas de la red aprenden a reconocer características muy simples: líneas horizontales, verticales, texturas básicas en la «imagen» del espectrograma. A medida que la información avanza a través de capas más profundas, estas características simples se combinan para identificar estructuras más complejas, como los husos de sueño o las ondas delta. [7] Finalmente, la red puede generar un «mapa de activación», que reduce toda esta información visual a un vector de números que representa la esencia de esa época de sueño.
Este vector luego puede alimentar a otro tipo de red, una Red Neuronal Recurrente (RNN), que es especialmente buena para manejar secuencias. [1] Una RNN puede tener en cuenta el contexto temporal: sabe que es muy poco probable pasar directamente de un sueño profundo (N3) a un sueño REM, por ejemplo. Al combinar el poder de las CNN para el análisis de patrones visuales y las RNN para el análisis de secuencias, estos modelos pueden lograr un rendimiento muy sofisticado. [1]
La capacidad de las redes neuronales para capturar relaciones no lineales en los datos es una de sus mayores fortalezas. [2] Las reglas que un humano utiliza para clasificar el sueño son complejas y no siempre lineales. La IA puede aprender estas sutilezas directamente de los datos, sin que se las programemos explícitamente.
La hora de la verdad: Validación y métricas de desempeño
Una vez que el modelo StageNet fue entrenado y probado en los 72 estudios de PSG que nunca antes había visto, llegó el momento de evaluar su desempeño. Los resultados se presentaron en una «matriz de confusión». Esta tabla es una herramienta fundamental para entender los errores de un modelo de clasificación. En ella, vemos qué porcentaje de las veces que el experto etiquetó una etapa como «Vigilia», el modelo también predijo «Vigilia» (en este caso, un impresionante 94%). También nos muestra los errores: por ejemplo, un pequeño porcentaje de las veces que el experto dijo «N2», el modelo predijo «N3» (3,7%) (Tabla 1). [5]

Tabla 1. Matriz de confusión.
La precisión general es una métrica útil, pero puede ser engañosa, especialmente si las clases están desbalanceadas (por ejemplo, pasamos mucho más tiempo en la etapa N2 que en la N1). Por eso, utilizamos otras métricas. El kappa de Cohen, que mide el acuerdo entre dos evaluadores (en este caso, el experto humano y la IA) tiene la ventaja de que corrige por el acuerdo que podría ocurrir solo por azar.
Una puntuación de kappa de 1 indica un acuerdo perfecto, mientras que 0 indica un acuerdo no mejor que el azar. En el estudio, la mediana del kappa fue de 0,85. [5] Generalmente, un kappa entre 0,81 y 1,00 se considera un acuerdo «casi perfecto». Esto sugiere que el rendimiento del algoritmo está a la par con el de un experto humano. De hecho, estudios previos han demostrado que el acuerdo entre diferentes expertos humanos (inter-evaluador) suele tener un kappa de alrededor de 0,76. [5] El hecho de que el algoritmo alcance un kappa de 0,85 en comparación con el estándar de oro es un resultado muy sólido.
Otras métricas importantes incluyen la sensibilidad (la capacidad del modelo para identificar correctamente una etapa específica) y la especificidad (la capacidad del modelo para identificar correctamente las otras etapas). El estudio reportó estas métricas para cada etapa del sueño, mostrando, por ejemplo, un «acuerdo positivo» (sensibilidad) del 92% para la etapa N2 y del 93% para la N3. [5]
El panorama general y el futuro
¿Qué significan todos estos números en la práctica? Significa que los algoritmos de aprendizaje profundo pueden clasificar las etapas del sueño con un nivel de precisión comparable al de los expertos humanos. [5] Esto tiene implicaciones enormes. Podría reducir drásticamente el tiempo y el costo asociados con el diagnóstico de los trastornos del sueño, permitiendo que más personas tengan acceso a una atención de calidad. [1]
Además, a medida que se acumulen más y más datos de polisomnografía de todo el mundo, estos modelos de IA podrán ser entrenados con conjuntos de datos aún más grandes y diversos. Esto no solo mejorará su rendimiento, sino que también nos permitirá explorar la heterogeneidad del sueño en diferentes poblaciones y condiciones clínicas. La IA podría ayudarnos a identificar nuevos subtipos de insomnio o a predecir qué pacientes con apnea del sueño tienen mayor riesgo de complicaciones cardiovasculares.
Por supuesto, la IA no es una panacea. Debemos ser conscientes de los desafíos. Uno de los más importantes es la interpretabilidad. Si bien un modelo puede ser muy preciso, si no podemos entender por qué toma una decisión particular, puede ser difícil confiar en él en situaciones clínicas críticas. La investigación en «IA explicable» (XAI) está trabajando para abrir estas «cajas negras» y proporcionar a los médicos información sobre el razonamiento del modelo. [12] Otro desafío es el sesgo. Si un modelo se entrena principalmente con datos de una población específica, puede no funcionar tan bien en otras. Debemos asegurarnos de que nuestros conjuntos de datos de entrenamiento sean diversos y representativos.
Al final, la promesa de la IA en la medicina del sueño no es reemplazar al médico, sino empoderarlo dándole herramientas más precisas, eficientes y perspicaces para que podamos dedicar más tiempo a lo que realmente importa: el cuidado de nuestros pacientes.
Como concluimos en nuestra charla con ACMES, estamos en el umbral de una nueva era: «En la medicina del sueño, el próximo gran descubrimiento podría hacerlo una máquina». Y para nosotros, en AIpocrates, la misión es asegurarnos de estar listos para entender, guiar y aprovechar ese descubrimiento cuando llegue.
Agradecimientos: A la Dra Leslie Vargas, miembro de AIpocrates y presidenta de ACMES por su generosa invitación a la III Master Class Insomnio y Somnolencia diurna excesiva.
Declaración de uso de IA: La casi totalidad de este documento fue generado por Gemini 2.5 Pro con base en la presentación que el autor realizó para la III Master Class el viernes 15 de agosto de 2025 en Armenia, Quindío. El autor se responsabiliza de su contenido.
Referencias bibliográficas
- Biswal, S., Sun, H., Goparaju, B., Westover, M. B., Sun, J., & Bianchi, M. T. (2018). Expert-level sleep scoring with deep neural networks. Journal of the American Medical Informatics Association, 25(12), 1643–1650.
- Esteva, A., Robicquet, A., Ramsundar, B., Kuleshov, V., DePristo, M., Chou, K., Cui, C., Corrado, G., Thrun, S., & Dean, J. (2019). A guide to deep learning in healthcare. Nature medicine, 25(1), 24–29.
- Norgeot, B., Quer, G., Beaulieu-Jones, B. K., Torkamani, A., Dias, R., Gianfrancesco, M., Arnaout, R., Kohane, I. S., Saria, S., Topol, E., Obermeyer, Z., Yu, B., & Butte, A. J. (2020). Minimum information about clinical artificial intelligence modeling: the MI-CLAIM checklist. Nature medicine, 26(9), 1320–1324.
- Olbrich, E., Claussen, J. C., & Achermann, P. (2011). The multiple time scales of sleep dynamics as a challenge for modelling the sleeping brain. Philosophical transactions. Series A, Mathematical, physical, and engineering sciences, 369(1952), 3884–3901.
- Cho, J. H., Choi, J. H., Moon, J. E., Lee, Y. J., Lee, H. D., & Ha, T. K. (2022). Validation Study on Automated Sleep Stage Scoring Using a Deep Learning Algorithm. Medicina (Kaunas, Lithuania), 58(6), 779.
- Li, C., Qi, Y., Ding, X., Zhao, J., Sang, T., & Lee, M. (2022). A Deep Learning Method Approach for Sleep Stage Classification with EEG Spectrogram. International journal of environmental research and public health, 19(10), 6322.
- Mandhouj, B., Cherni, M. A., & Sayadi, M. (2021). An automated classification of EEG signals based on spectrogram and CNN for epilepsy diagnosis. Analog Integrated Circuits and Signal Processing, 108, 101-110.
- Hastie, T., Tibshirani, R., & Friedman, J. (2021). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. New York: Springer.
- Sidey-Gibbons, J. A. M., & Sidey-Gibbons, C. J. (2019). Machine learning in medicine: a practical introduction. BMC medical research methodology, 19(1), 64.
- Pfob, A., et al. (2022). Machine learning in medicine: a practical introduction to techniques for data pre-processing, hyperparameter tuning, and model comparison. BMC medical research methodology, 22(1), 282.
- Roy, Y., Banville, H., Albuquerque, I., Gramfort, A., Falk, T. H., & Faubert, J. (2019). Deep learning-based electroencephalography analysis: a systematic review. Journal of Neural Engineering, 16(5), 051001.
- Zaschke, P., Maurer, M. C., Hempel, P., et al. (2025). A somnologist’s guide to explainable deep neural networks for sleep scoring. Somnologie, 29, 85–92.
