Juan Camilo Hernández Ruiz. Químico Farmacéutico. Universidad de Antioquia. MSc en Economía de la salud. Universidad CES. Miembro fundador AIPOCRATES. Twitter: @CamiloHR1986. Linkedin: Juan Camilo Hernández Ruiz
Eduardo Dueñas Manosalva. Médico y Cirujano General. Especialista en Derecho Médico. Master Internacional en Administración en Salud, MBA. Candidato a PHD en Economía y Finanzas. Docente Universitario. Twitter: @EduardoDueñasM. Linkedin: Eduardo Dueñas Manosalva.
Durante las últimas dos décadas, no solo la digitalización, sino también la gestión de datos, ha tomado un papel importante en la sociedad. En el sector de la salud, se convierte en un pilar fundamental para gestionar la salud de las personas. Cada vez es más común evidenciar cómo en los diferentes campos se han aplicado herramientas de inteligencia artificial para utilizar y gestionar gran cantidad de datos y poder obtener la mejor información de estos para las mejores decisiones en salud.
A medida que se tenga más disponibilidad de datos en formatos digitales, se pueden aplicar técnicas de inteligencia artificial (1), para dar respuesta a la salud de los individuos, comunidades y poblaciones. Por otra parte, la automatización de los procesos apoyada con las diferentes herramientas tecnológicas (software) ha sido de gran utilidad para brindar un manejo considerable a la gran cantidad de datos disponibles, ya que pueden interpretar datos con mayor facilidad, lo que permite tomar mejores decisiones con el fin de alcanzar objetivos planeados dentro de un proceso (2), es decir, permite una mejor gobernanza clínica y administrativa en las diferentes instituciones.
La inteligencia artificial requiere de la participación e integración de diferentes disciplinas de conocimientos como son matemática, informática, economía, entre otras. En la actualidad, la inteligencia artificial ha pasado a un campo más real que teórico y esto permite ver grandes avances en los campos que han implementado inteligencia artificial en sus procesos (3).
La industria farmacéutica ha sido una de las áreas que más beneficio ha obtenido con la interacción de la inteligencia artificial, ya que con esta, se ha podido facilitar y agilizar los procesos de descubrimiento y desarrollo de fármacos (4), lo que contribuye a mejorar la salud de la población en general. Además, por medio de la inteligencia artificial, se pueden realizar minería de datos con el fin de identificar con mayor facilidad problemas relacionados con medicamentos, determinando las poblaciones más propensas a presentar diferentes reacciones adversas a medicamentos o ineficiencias operativas.
Modelos de predicción computacional
La industria farmacéutica requiere una interacción activa con nuevas tecnologías como lo es la inteligencia artificial, mediante algoritmos computacionales permite agilizar los procesos de descubrimiento y desarrollo de fármacos, así como el desarrollo científico innovador, replanteando la idea de utilizar los métodos de inteligencia artificial en el descubrimiento y fabricación de medicamentos. A pesar de que este mecanismo ha avanzado en los últimos años, se evidencian algunas falencias en cuanto a la calidad de los datos y la heterogeneidad de los mismos, lo que retrasa la ejecución adecuada de los modelos de predicción computacional (6).
La combinación entre inteligencia artificial y farmacología es de gran ayuda para avanzar en los desarrollos de medicamentos para patologías de alta complejidad, puesto que se pueden tener en cuenta las variaciones moleculares que se presentan en un grupo de individuos, lo que permite obtener algunas respuestas de los tratamientos o reacciones adversas a los medicamentos (6). Además, se ha convertido en una herramienta esencial en la gestión farmacéutica para los programas y modelos de atención de enfermedades crónicas, de alto costo, bajo el concepto de evitabilidad y gestión integral del riesgo en salud.
Para garantizar éxito en el diseño de modelos de predicción computacional, se deben establecer unas estrategias adecuadas y claras, iniciando por la selección apropiada de los datos ( Fig.1 ) (Libbrecht y Noble, 2015). Luego de tener los datos seleccionados, estos se ajustan a diferentes modelos, con el fin de determinar cuál es el modelo de predicción computacional más adecuado para aplicarlo a datos que se asimilen a datos clínicos (6).
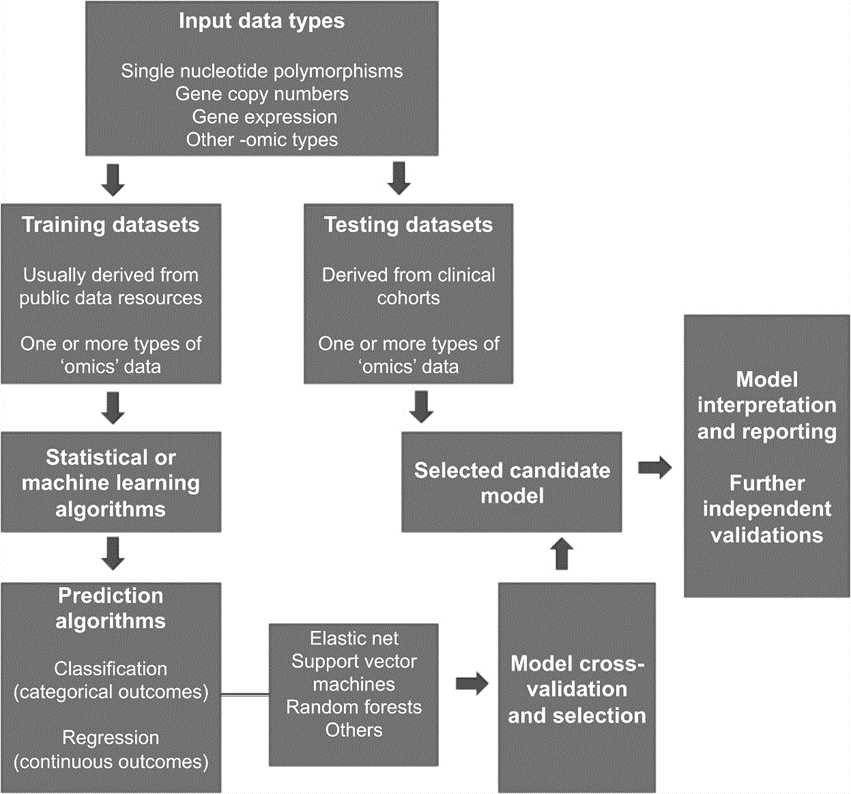
(Fig.1) (Libbrecht y Noble, 2015)
La industria farmacéutica se está interesando cada vez más en la implementación en sus procesos de herramientas con modelos de inteligencia artificial, incentivando así la investigación para el descubrimiento y desarrollo de medicamentos. Estas interacciones permiten reunir grandes cantidades de datos de diferentes fuentes de información, como son las fuentes académicas o los resultados obtenidos por los diferentes ensayos clínicos (7).
La inteligencia artificial a través de la modelación ha permitido agilizar los procesos de descubrimiento de nuevos fármacos (3), pero debemos ser conscientes que se tienen algunos pendientes como la calidad y la cantidad de la información de los datos, que genera una barrera para el éxito del proceso, lo que conlleva a errores en los modelos de predicción (8). El desafío en la actualidad para sobrepasar estas barreras es crear algoritmos que aprendan automáticamente a hacer frente a la gran cantidad de datos heterogéneos que son el resultado de ensayos experimentales, por medio de mecanismos biológicos.
En la práctica diaria de los procesos generales y especiales en los servicios farmacéuticos (9) se deben realizar diferentes actividades que generan mucho desgaste para el personal, que deben realizarlas de forma manual, convirtiéndose en prácticas poco productivas en términos de tiempo y reprocesos operativos. Entonces, la premisa es ¿cómo llevar la gestión farmacéutica a otro nivel? La automatización de muchos procesos dentro de los servicios farmacéuticos ha ganado mayor protagonismo en los últimos tiempos, siendo cada vez más común ver diferentes software con algoritmos para determinar ineficiencias farmacológicas del gobierno clínico, administrativo y logístico, siendo las ineficiencias en salud un tema de gran preocupación para los países, por el hecho de aumentar la probabilidad de resultados desfavorables para los pacientes y de costos evitables para los sistemas de salud.
Un estudio colombiano (10) se realizó con el objetivo de prevenir errores de medicación y describir e identificar por medio de desarrollos tecnológicos de algoritmos de decisión multicéntrico, algunas ineficiencias farmacológicas como interacciones farmacológicas, duplicidades terapéuticas, ajuste de dosis para pacientes con falla renal o hepática y medicamentos contraindicados en poblaciones especiales, entre otras.
Se realizó con una metodología de identificación de las necesidades, análisis de las fuentes de información, diseño y creación de modelos de datos en el Data warehouse (DWH), creación de ETLs (Extract, Transform and Load) para extracción automática de los datos, creación de ETLs para cruzar las diferentes fuentes de datos con el fin consolidar los resultados de cada tipo de ineficiencia y generación automática con el resultado de la ineficiencia y envío a correos electrónicos con el documento de soporte. El estudio permitió identificar 1.015 principios activos y 4.604 presentaciones de medicamentos, distribuidos en la tabla 1, según tipos de ineficiencias.
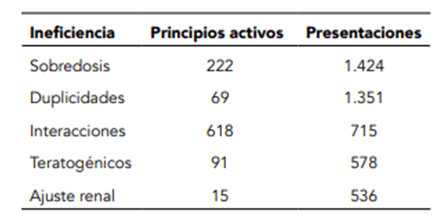
Tabla 1. (Carlos Gómez y Newar Giraldo, 2021)
La automatización de procesos dentro de la identificación de ineficiencias, tiene mucho valor por el hecho de prevenir errores de medicación que se han convertido en una preocupación a nivel mundial. En EE. UU., los errores de medicación provocan al menos una muerte diaria y daños en aproximadamente 1,3 millones de personas al año, generando un costo mundial asociado de US$ 42.000 millones al año (11).
Bajo esta compleja situación, las diferentes alternativas basadas en inteligencia artificial se convierten en aliados para automatizar procesos, liberando tiempo a los diferentes actores de los servicios farmacéuticos, mejorando el tiempo dedicado a realizar validación, monitoreo y análisis de los resultados obtenidos de las estrategias implementadas por medio del software y realizar actividades más personalizadas con los pacientes, como son educación, consulta farmacéutica, rondas de seguridad, seguimiento identificación de alertas, desviaciones hasta toxicidad y fallas terapéuticas, entre otras.
Una de las actividades más importantes dentro de los procesos especiales de los trabajadores del servicio farmacéutico es la identificación de interacciones farmacológicas, las cuales modifican el efecto de un fármaco por la acción de otro. Dicha actividad requiere de un amplio conocimiento de los medicamentos, además de destinar gran cantidad de tiempo para identificar las interacciones que se pueden presentar en las diferentes fórmulas emitidas por el personal médico de cada institución o la doble prescripción frecuente cuando intervienen varias instituciones de salud en el ciclo de atención de una patología. En la actualidad, se evidencian algunos softwares que facilitan este proceso automatizando la identificación y clasificación de las posibles interacciones que se pueden encontrar sobre todo en pacientes polimedicados.
Un software diseñado en una institución médica en México por medio del listado básico de medicamentos institucionales (12) se construyó por medio de información del PLM México, diccionarios médicos, vademécum y micromedex, permitió identificar 540 interacciones farmacológicas que se pueden presentar con mayor frecuencia. Luego de identificar estas interacciones, se generó un modelo de clasificación mediante la plataforma Weka utilizando un algoritmo Naïve Bayes el cual predice la posibilidad de clasificar las interacciones en leve, moderada o grave, se realizaron pruebas utilizando el método de validación cruzada con 10 pliegues. Las pruebas de validación fueron comparadas con el resultado obtenido con el algoritmo Random Forest, utilizando nuevamente el método de validación cruzada con 10 pliegues.
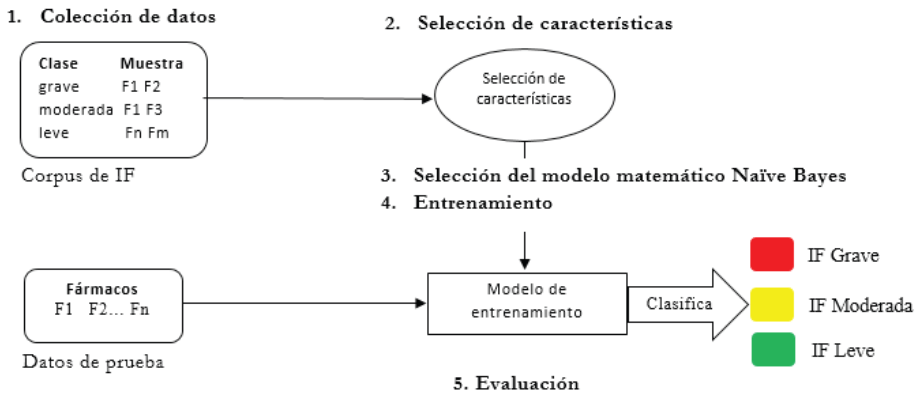
Figura 2. (Colmenares y Morales, 2018)
La selección de modelo matemático fue Naïve Bayes, el cual es considerado unos de los algoritmos más eficientes y efectivos de aprendizaje inductivo para el desarrollo de aprendizaje automático y minería de datos (13). Este modelo se construyó mediante un proceso de cinco etapas del ciclo del diseño. En la primera etapa de colección de datos se recolectó la información de muestras de interacciones farmacológicas. En la segunda de selección de características se seleccionaron los nombres de los dos fármacos que producen la interacción farmacológica. En la tercera etapa se analizó el modelo matemático Naïve Bayes. En la cuarta etapa se generó el modelo de entrenamiento (ME) con base al modelo matemático NB y en la quinta etapa se realizaron las pruebas de clasificación.

Tabla 2. (Colmenares y Morales, 2018)
El algoritmo de Naïve Bayes dio como resultado una precisión de 79,1 % mientras que el algoritmo Random Forest dio una precisión 51,7 %. Se observó que al utilizar el método de validación cruzada con 10 pliegues, el algoritmo que presentó mejores resultados fue el algoritmo NB con relación al algoritmo de Random Forest.
Todas estas herramientas tecnológicas basadas en algoritmos matemáticos de decisión han permitido identificar ineficiencias farmacológicas, lo que permite prevenir los errores de medicación más frecuentes y generar valor a los sistemas de salud. Es probable que una atención ineficiente en cualquier parte del sistema, impida la atención a otros pacientes los cuales podrían haber sido tratados si los recursos en término de tiempo del personal de los servicios farmacéuticos se hubieran distribuido de una forma más óptima, es por esto que la identificación y clasificación de ineficiencias y su gestión es un objetivo muy importante sobre todo para los sistemas de salud que requieren dar solución a necesidades infinitas con recursos limitados.
Referencias.
1. Full Text PDF [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://onlinelibrary.wiley.com/doi/pdfdirect/10.1002/cpt.1795
2. Agrawal – 2018 – Artificial Intelligence in Drug Discovery and Deve.pdf [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://www.longdom.org/open-access/artificial-intelligence-in-drug-discovery-and-development-2329-6887-1000e172.pdf
3. Yang et al. – 2019 – Concepts of Artificial Intelligence for Computer-A.pdf [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://pubs.acs.org/doi/pdf/10.1021/acs.chemrev.8b00728
4. Texto completo [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://www.cell.com/article/S0165614719301695/pdf
5. La inteligencia artificial en el sector salud: Promesas y desafíos | Publications [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://publications.iadb.org/publications/spanish/document/La-inteligencia-artificial-en-el-sector-salud-Promesas-y-desafios.pdf
6. Koromina et al. – 2019 – Rethinking Drug Repositioning and Development with.pdf [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://www.liebertpub.com/doi/pdf/10.1089/omi.2019.0151
7. Savage – 2021 – Tapping into the drug discovery potential of AI.pdf [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://media.nature.com/original/magazine-assets/d43747-021-00045-7/d43747-021-00045-7.pdf
8. (PDF) Big Data and Artificial Intelligence Modeling for Drug Discovery [Internet]. [citado 22 de febrero de 2024]. Disponible en: https://www.researchgate.net/publication/335808180_Big_Data_and_Artificial_Intelligence_Modeling_for_Drug_Discovery
9. De la calidad de los medicamentos C o. A, de las materias primas necesarias para su elaboración y demas productos autorizados por ley para lacomercialización en dicho establecimiento. DM o. Se considera establecimiento farmacéutico a todo establecimiento dedicado a la [Internet]. Gov.co. [citado el 23 de febrero de 2024]. Disponible en: https://www.minsalud.gov.co/sites/rid/Lists/BibliotecaDigital/RIDE/DE/DIJ/Resoluci%C3%B3n_2955_de_2007.pdf
10. Carlos A. Gómez , Johan Granados , Camilo Lezcano Ángela Segura , Johana Ríos , Newar A. Giraldo. ALGORITMOS DE DECISIÓN MULTICRITERIO PARA LA IDENTIFICACIÓN DE INEFICIENCIAS FARMACOLÓGICAS. School of Pharmaceutical and Food Sciences ISSN 0121-4004. el 11 de noviembre de 2021;2145–660.
11. OMS | La OMS lanza una iniciativa mundial para reducir a la mitad los errores relacionados con la medicación en cinco años [Internet]. WHO. [citado 22 de febrero de 2024]. Disponible en: http://www.who.int/mediacentre/news/releases/2017/ medication-related-errors/es/
12. de Ingenieria F. Revista Ingeniería Investigación y Tecnología [Internet]. Unam.mx. [citado el 23 de febrero de 2024]. Disponible en: https://www.revistaingenieria.unam.mx/numeros/v20n2-02.php
13. Cloudfront.net. [citado el 23 de febrero de 2024]. Disponible en: https://d1wqtxts1xzle7.cloudfront.net/77239949/pdf-libre.pdf?1640350268=&response-content-disposition=inline%3B+filename%3DImplementasi_Particle_Swarm_Optimization.pdf&Expires=1708206264&Signature=axFqLzJCi0pV8U~VElWsc6BlxzwnX97i88XmiBNkhKec-xlsoppYlhODtQVuZHjtVo~KgrfJphGpau~WVSBJa7OGsrOZptXPWwsgmIpCLK6ClVziTiGlXMuRGSuKR4Cr-ki8Vb7UEd1rQupJm2JvehZhcNiQqeWf2J-VvoH~m03et7cD6jEtEe2SmHOLx8hPiBU8Q5O7lzD4~Nrgz3wMYdIfyuih5k8JhlPrWxrRiEEbQZhE9PmycLvkeDqgbueFKuII9Vov–Z3tHVjMpjGrjQgLjmohi30ihPnoNtkIKFwl5SgVxq~QRq~qqn8sdDlum2d15BoHuq2D-HGURfE1w__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
