Natalia Sánchez1, Adriana Aya1, Edwin Pulido1, Heidy Trujillo1, Andrés F. Cardona1
Instituto de Investigación y Educación, Centro de Tratamiento e Investigación sobre Cáncer Luis Carlos Sarmiento Angulo (CTIC), Bogotá, Colombia
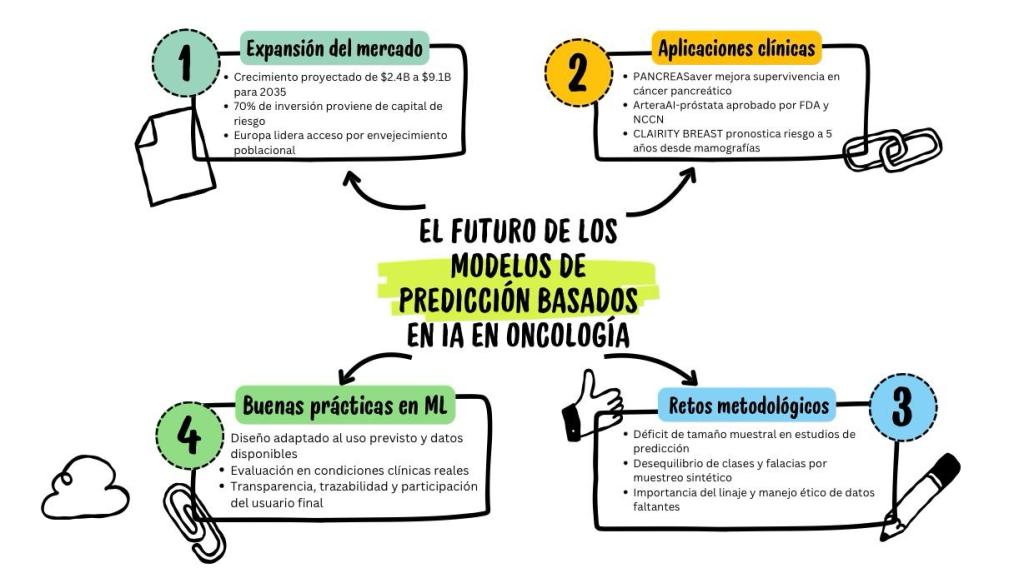
Perspectiva y expansión del mercado
Crecimiento del mercado y focos de uso
Diversos actores han estimado que el mercado de la inteligencia artificial (IA) en oncología crecerá de 2,4 billones de dólares en 2025 a 9,1 billones de dólares en 2035, lo que representa una tasa de crecimiento anual compuesta (CAGR, por su sigla en inglés) del 14,1 % (1).
Por el momento, el uso de la IA se ha concentrado en la integración, evaluación e interpretación de datos en tiempo real (Real World Data and Evidence Analysis), en la generación de soluciones para la detección temprana del cáncer, el desarrollo de terapias personalizadas, y la generación de modelos diagnósticos avanzados.
Estos ejes han concentrado a más de 70 actores y desarrolladores clave involucrados en la gestión de soluciones para el cáncer, entre los que más del 50% utiliza modelos basados en aprendizaje automático (ML, por su sigla en inglés), incluyendo la integración de soluciones tecnológicas patentadas (1).
Durante los últimos 5 años, numerosos inversionistas públicos y privados han permitido la movilización de 6 billones de dólares, provenientes, en el 70% de los casos, de fondos de capital de riesgo. En paralelo, se logró la gestión de 2.770 patentes segmentadas por neoplasias sólidas y hematológicas enfocadas en el ámbito hospitalario, derivadas de la industria farmacéutica y de instituciones focalizadas en investigación.
Distribución geográfica y terapias digitales
Geográficamente, el mercado global de la IA en oncología se distribuye entre América del Norte, Europa y Asia/Pacífico, que representan más del 88% de la capacidad instalada. En el presente año, el 33% del acceso se concentra en Europa, probablemente debido al impacto del rápido envejecimiento poblacional, así como a la incidencia y la carga de enfermedad del cáncer a nivel continental.
No obstante, en la siguiente década se espera una transformación significativa en Asia/Pacífico, con un crecimiento cercano al 15% (1). Para 2024, el número de aplicaciones digitales en salud ascendía a 337.000, con especial énfasis en patologías crónicas y uso en los países con ingresos altos (2).
La aceleración progresiva del acceso y la cobertura a las herramientas digitales ha facilitado la introducción y la adopción de 360 terapias con base digital (software-based digital therapies), de las cuales 140 están aprobadas regulatoriamente para uso terminal por los pacientes en el hogar. Simultáneamente, la Food and Drug Administration (FDA, Estados Unidos) y otras agencias regulatorias han incluido en sus listas de evaluación más de 1.000 dispositivos médicos basados en IA/ML (77% de ellos en radiología), sentando un precedente para la evaluación de solicitudes específicas en oncología (3).
Actores destacados
Los desarrolladores que combinan amplios conjuntos de datos multimodales con calidad y validación clínica disfrutan de acceso privilegiado a la inversión, con un retorno potencialmente demostrable. En este sentido, algunas de las figuras más destacadas en el mercado potencial son Berg (parte de BPGbio), CancerCenter.AI, Concert AI, GE Healthcare, IBM Watson Health, iCAD, JLK Inspection, Median Technologies, Path AI, Tempus, PathosAI y Roche Diagnostics.
Neoplasias, intervenciones y aplicaciones
Por tipo de neoplasia, el cáncer de mama lidera la participación en el desarrollo de la IA con el 28.2%, seguido por el cáncer colorrectal, de próstata, de pulmón y los tumores cerebrales.
Según el tipo de intervención terapéutica, los ejemplos más representativos están asociados con la radioterapia (41%) seguidos por modelos pronósticos y predictivos asociados con el uso de la inmunoterapia (37%) (3). Por aplicación, la expansión más significativa del mercado está relacionada con la detección y el diagnóstico avanzado del cáncer (43%), seguida del desarrollo de nuevos fármacos (38%).
Casos innovadores y resultados clínicos
Algunos ejemplos innovadores y revolucionarios del mercado de la IA en oncología incluyen la plataforma PANCREASaver, diseñada por el Hospital Universitario Nacional de Taiwán para detectar lesiones pancreáticas menores de 2 cm con una precisión del 86%, lo que permitió mejorar la supervivencia global a 5 años (>80%) (4,5).
La IA se ha convertido en el motor analítico de la oncología de precisión, facilitando el análisis avanzado e integrado del genoma, la transcriptómica y la proteómica. En adición, la combinación con la patología digital, la radiómica y la radiogenómica ha permitido la implementación efectiva de diversas terapias dirigidas.
La aprobación de la prueba ArteraAI-próstata por la FDA y la NCCN (National Comprehensive Cancer Network) permite identificar pacientes que requieren intensificación terapéutica en etapas tempranas de la enfermedad. La prueba está respaldada por la evidencia 1B, que legitima el uso de algoritmos estructurados para la evaluación pronóstica en hombres con cáncer de próstata temprano.
En similar dimensión, se encuentra CLAIRITY BREAST, la primera herramienta autorizada para pronosticar el riesgo de cáncer de mama a 5 años a partir de mamografías de rutina. Este sistema integra tecnología de Siemens Healthineers, incluyendo 70 aplicaciones y modelos de IA entrenados con 1.400 millones de estudios provenientes de un portafolio diverso (7).
Mientras tanto, diferentes modelos ultracompactos optimizan la detección de nódulos pulmonares eliminando el ruido derivado de los vasos sanguíneos, segmenta, mide y evalúa las regiones de interés del parénquima pulmonar y toma decisiones comparando la variación de los nódulos respecto de los estudios previos (8). Este sistema, entre otros, reduce el tiempo de lectura del radiólogo en 26%, reduce el número de lesiones no detectadas en 29% y permite establecer protocolos adaptados a la edad y según múltiples criterios clínicos específicos (9,10).
Armonización regulatoria
Por el increíble volumen de dispositivos y modelos basados en IA en oncología y otras ciencias, la FDA en conjunto con Health Canada y con la Agencia Regulatoria de Medicamentos y Productos Sanitarios del Reino Unido (MHRA) identificaron conjuntamente diez principios rectores que orientan el desarrollo de Buenas Prácticas para modelos de ML (GMLP) con la intención de promover la eficacia y calidad favoreciendo la armonización internacional a partir del consenso (10).
Buenas prácticas para el desarrollo de dispositivos médicos con base en modelos de ML (Principios rectores)
- Se debe aprovechar la experiencia multidisciplinaria a lo largo de todo el ciclo de vida del producto.
- Se asegura la implementación de buenas prácticas de ingeniería de software y de seguridad.
- Los participantes y los conjuntos de datos derivados de los estudios clínicos son representativos de la población de pacientes que se prevé evaluar.
- Los conjuntos de datos de entrenamiento son independientes de los de prueba.
- Los conjuntos de datos de referencia seleccionados se basan en los mejores métodos disponibles.
- El diseño del modelo se adapta a los datos disponibles y refleja el uso previsto del dispositivo.
- El enfoque se centra en el rendimiento del equipo humano-IA.
- Las pruebas demuestran el rendimiento del dispositivo en condiciones clínicamente relevantes.
- Los usuarios reciben información clara y esencial que les permite tomar decisiones.
- La valoración asegura el rendimiento de los modelos implementados y la gestión de los riesgos asociados al reentrenamiento.
¿Realmente necesitamos más modelos de predicción en oncología?
Panorama de modelos existentes y evaluación crítica
Recientemente, Hueting y colaboradores establecieron que existen más de 900 modelos para respaldar la toma de decisiones en cáncer de mama (incluidos >400 dirigidos a predecir la mortalidad y >200 para estimar la recurrencia) (12) y >100 arquetipos pronósticos para evaluar la supervivencia en cáncer gástrico (13). Considerando este contexto, antes de desarrollar un nuevo modelo, cabe considerar el impacto potencial y el aporte crítico y real a la evidencia existente (14,15).
La revisión sistemática de la evidencia puede contribuir al desarrollo de nuevos modelos para identificar predictores de uso común o garantizar la no recurrencia de fallas o deficiencias críticas en los existentes. En este sentido, algunos de los puntos más críticos incluyen el diseño y la estructura adecuados de los métodos, la exposición completa de la información que los conforma, y el control adecuado de sesgos y de la sobreinterpretación de los resultados (16).
Participación del usuario final y utilidad en entornos reales
Es por esto, que desde el principio, se debe contemplar y vincular la participación del usuario final, incluyendo diversos profesionales del ámbito sanitario, los pacientes y el público en general. También parece fundamental garantizar la relevancia, la utilidad y la fiabilidad en entornos reales (17).
La diversidad de los participantes asegura que los modelos reflejen las experiencias vividas, prioricen los resultados más importantes para los afectados y aborden las inquietudes sobre el uso de los datos, la equidad y la transparencia. El enfoque colaborativo también permite optimizar la precisión, la comprensibilidad y la utilidad práctica de los modelos de predicción mediante la retroalimentación de los usuarios finales, lo que se ajusta dinámicamente a sus necesidades.
¿Cómo confiar en el diseño del estudio y en su muestra?
Importancia del diseño y tamaño muestral
El diseño de los estudios es un componente crucial, ya que guía la recopilación de datos, la elección de los métodos de análisis y la validez de los hallazgos. En la investigación sanitaria, donde los hallazgos impactan en la atención al paciente, las políticas de salud pública y la asignación de recursos, un diseño deficiente puede derivar en conclusiones erróneas, desperdicio de recursos e incluso en daños si se implementa en un flujo de trabajo.
El tamaño de la muestra es un componente crítico del diseño de todos los estudios y una consideración clave en la investigación sobre IA predictiva. Tseyage y colaboradores valoraron con detalle el tamaño de muestra de múltiples estudios orientados a desarrollar modelos de predicción para evaluar resultados binarios en oncología, comparando el tamaño de muestra empleado con el mínimo requerido para un modelo basado en regresión (Nmin). De la totalidad de los estudios revisados, solo en el 47% de los casos se pudo calcular el Nmin y, en la tercera parte de estos, se pudo estimar con precisión el riesgo para minimizar el sobreajuste. Llamativamente, cuando se estimó la mediana del déficit en el número de participantes con el evento, esta fue >300 (18).
Requisitos de datos en ML y brechas metodológicas
Los algoritmos de ML suelen requerir conjuntos de datos más grandes debido a su capacidad para modelar relaciones e interacciones complejas no lineales, con requisitos que varían según el algoritmo específico. A diferencia de los métodos de regresión, muchos enfoques de ML carecen de fórmulas definidas para determinar el tamaño de muestra ideal. Por este motivo, los investigadores en cáncer generalmente deben basarse en estudios de simulación, curvas de aprendizaje o mesetas para evaluar el rendimiento y determinar el tamaño de muestra óptimo (19).
Otras metodologías emergentes incluyen los enfoques bayesianos que estiman los tamaños mínimos de muestra, examinando el rendimiento, la degradación y la estabilidad del modelo. Sin embargo, esta brecha metodológica de la IA en los estudios de cáncer resalta la necesidad de desarrollar métodos de cálculo estandarizados para la evaluación de la muestra ideal.
¿Cómo optimizar el diseño de los estudios y la representatividad de los datos?
Representatividad de la población objetivo
En diversos escenarios clínicos, incluida la oncología, es importante que los datos utilizados para entrenar un modelo de predicción sean representativos de la población objetivo en la que se utilizará el modelo. La representatividad de la información garantiza que el modelo cuente con la diversidad demográfica, biológica, clínica y socioeconómica de la población, reduciendo los sesgos que podrían dar lugar a predicciones inexactas o resultados inequitativos para los subgrupos subrepresentados. Sin dicha representatividad, los modelos corren el riesgo de perpetuar las disparidades, ya que no reflejan la realidad.
De forma similar, el uso de datos existentes recopilados con fines distintos del desarrollo de un modelo de predicción, por mera conveniencia, requiere una cuidadosa consideración, ya que podrían no reflejar el comportamiento de las poblaciones objetivo actuales, presentar problemas de calidad o revelar potenciales predictores relevantes.
Desequilibrio de clases
El desequilibrio de clases se refiere a las diferencias en el número de individuos con y sin el resultado en un conjunto de datos específico. Este desequilibrio es natural y previsible, y refleja la realidad de las poblaciones evaluadas, y no representa un problema al desarrollar un modelo de predicción.
Sin embargo, el submuestreo o el uso de enfoques sintéticos como la técnica de muestreo sintético de minorías (SMOTE), utilizados usualmente como soluciones para el desequilibrio, manipulan artificialmente los datos para equilibrar las frecuencias de los resultados, distorsionando la distribución subyacente y socavando la representatividad real de la información. Lejos de ser correctivos, estos enfoques introducen falacias y perjudican la validez y la generalización del modelo resultante (20).
Procedencia y linaje de los datos
En igual medida, detallar la procedencia de los datos, el historial de su fuente, los métodos de recopilación y los procedimientos utilizados para su gestión constituye un eje crucial para la protección de la calidad. La información detallada permite verificar su autenticidad, lo que dificulta la introducción inadvertida de datos manipulados.
Sin una procedencia detallada, la comunidad científica no puede distinguir eficazmente entre hallazgos clínicos genuinos y resultados espurios, lo que podría dar lugar a modelos defectuosos que, al implementarse en la práctica clínica habitual, podrían poner en riesgo la seguridad de los pacientes. Establecer el linaje de los datos aporta transparencia a la investigación, permitiendo un formato auditable que favorece los procedimientos éticos esenciales para garantizar que los modelos de predicción se basen en la integridad.
Manejo de datos faltantes
La planificación cuidadosa de los procedimientos también minimiza el volumen de datos faltantes. No obstante, cuando inevitablemente surgen datos faltantes, estos pueden introducir sesgos que limitan la generabilidad. Por lo general, se debe evitar descartar a los individuos con valores faltantes o extremos para realizar un análisis de caso completo, utilizando técnicas como la imputación múltiple (reemplazo de valores faltantes mediante múltiples estimaciones plausibles), la imputación por regresión (usando modelos ajustados para predecir los valores faltantes) y el uso de valores de referencia (21).
En algunos enfoques de modelación, el manejo de los datos faltantes está integrado en el proceso de entrenamiento del modelo (por ejemplo, en XGBoost).
Continúa con la parte 2 en la siguiente publicación
