Autor: Andres Rico. MD Internista. CEO AIpocrates
Introducción

Como se mencionó en una columna previa ¿Es deshonesto usar Modelos de Lenguaje a Gran Escala (IA) para resumir artículos médicos?, los modelos Generative Pre-trained Transformers (GPT), ahora llamados modelos fundacionales, tienen grandes capacidades operativas multimodales al aceptar texto, voz e imagen como entrada; desde que herramientas del tipo LLM como ChatGPT, Gemini, Claude, entre otros, irrumpieron en el escenario de la vida diaria, muchos médicos, investigadores y docentes se han lanzado a usarlas con entusiasmo por su utilidad para acelerar tareas, mejorar redacción, estructurar o sintetizar información, sin embargo, para aprovechar estas capacidades se requiere estructurar una solicitud o “prompt” de alta calidad y el resultado será casi mágico. Pero, ahí está el problema: la magia no existe, y nada sustituye al método.
Usar un modelo de lenguaje en salud no es simplemente “saber escribir un buen prompt”. Involucra comprender las limitaciones del modelo, las implicaciones éticas y técnicas del uso de datos clínicos, el riesgo de reproducir sesgos y errores, y, sobre todo, no confiar ciegamente en la respuesta, siempre hay el deber de verificar. Bienvenidos a una sesión de reflexión y responsabilidad.
La ilusión de saber usar IA solo por escribir prompts
Hoy, muchas personas se autodenominan “expertos en GPT” por saber escribir prompts ingeniosos, que difunden en vídeos de YouTube y en otras redes sociales, mostrando los “milagros” de estos modelos. Sin embargo, conocer el modelo desde la superficie es como decir que sabes practicar medicina por saber usar un estetoscopio o aprendiste a nadar en una bañera. El prompt engineering es apenas la puerta de entrada; lo verdaderamente complejo —y crítico— ocurre detrás.
Los modelos de lenguaje no piensan, no entienden el contexto clínico, su fortaleza está en generar texto coherente, estos modelos funcionan bajo inferencias probabilísticas, que pueden lucir confiables, pero estar totalmente equivocadas.
Por esta razón, escribir un prompt bien formulado no garantiza una respuesta adecuada, válida, ni ética. Los modelos tampoco conocen la veracidad o la relevancia científica de sus respuestas; especialmente cuando se trata de decisiones en salud, estos modelos generales (sin un ajuste fino ni una retroalimentación, RAG (Retrieval-Augmented Generation) no tienen la capacidad de distinguir lo cierto de lo falso.
Esa “verborrea convincente” lleva a muchos a asumir como verdad lo que es apenas una predicción sintácticamente plausible. Si el usuario no tiene la formación para validar la respuesta, puede amplificar errores en lugar de evitarlos.
Por eso, usar GPT en medicina no puede reducirse a saber “hablarle bien” al modelo, no basta con preguntar bonito. Implica que hay que saber interpretar críticamente las respuestas emitidas, integrarlas con conocimiento clínico y, sobre todo validar contra la evidencia, reconocer límites y asumir responsabilidades, no sustituir el juicio humano por una red neuronal entrenada con texto.
No, tu archivo de Excel no es un dataset ni una base de datos clínica

En ciencia de datos en salud, podemos hacer una metáfora poderosa con una memorable película colombiana “Perder es Cuestión de Método”, porque podemos perder el rumbo si no tenemos un método y no es cuestión de tecnología, sino de fundamento.
En medicina, el camino del fenómeno clínico al análisis computacional es largo, técnico y delicado, comienza entendiendo la diferencia entre una hoja de cálculo y una base de datos.
Hoy en día, muchos profesionales suben archivos de Excel con datos clínicos —sin anonimización, sin curación, sin armonización, sin normalización, con valores ausentes, repetidos o mal registrados— variables con definiciones operacionales inadecuadas, con falta de claridad, ambiguas, sin criterios estandarizados para su medición, que no capturan adecuadamente el fenómeno que intentan medir. Esa hoja de Excel desorganizada, con valores mal etiquetados y sin trazabilidad, ¡Spoiler!, eso no es un dataset, no es ciencia de datos. Es una amenaza para la toma de decisiones, aunque las presentan como si fueran bases de datos listas para análisis con herramientas de inteligencia artificial.
Recoger variables clínicas (signos vitales, resultados de laboratorio, determinantes sociales, escalas clínicas) no convierte automáticamente tu hoja de cálculo en un dataset clínico estructurado. El camino es más complejo: registro de variables → datapoint → dataset → base de datos → data warehouse → data lake → lakehouse.


- El datapoint es la unidad mínima de observación digitalizada.
- Un dataset es un conjunto estructurado de datapoints homogéneos.
- La base de datos almacena y organiza múltiples datasets con esquemas relacionales. Estas bases pueden ser integradas en un data warehouse,
- El data warehouse agrega múltiples bases de datos orientadas a consulta analítica.
- El data lake permite almacenar datos estructurados y no estructurados en su forma nativa.
- El lakehouse es la evolución moderna: combina la estructura del warehouse con la flexibilidad del lake, habilitando análisis de alto nivel y entrenamiento de modelos de IA con datos confiables.
Cada paso requiere una definición, una estructura, gobernanza y calidad, son elementos cruciales para la validez y reproducibilidad. Saltar estos pasos —como cargar un Excel defectuoso directamente en una IA para “ver qué dice”— no solo es ingenuo, es peligroso. La mala calidad del dato se amplifica con el uso de algoritmos, y lo que debería ser una ayuda se convierte en un multiplicador de errores o una conclusión científica inválida.
Y antes de hablar de IA, toca hablar de epidemiología, estadística, interoperabilidad y estándares. Aquí es donde entra el verdadero papel de la epidemiología y la estadística: no como disciplinas que “serán reemplazadas por la IA”, sino como las que permiten definir el marco lógico para el análisis, el muestreo, la limpieza y la interpretación del dato. La estadística y la epidemiología no morirán por culpa de la IA. Son más necesarias que nunca. La primera permite evaluar la calidad y distribución de los datos; la segunda, diseñar los estudios que permiten hacer inferencias válidas a partir de ellos. Sin estas metodologías, la IA en salud es solo una herramienta sofisticada aplicada al caos.
Porque sin diseño de estudio, sin validación de los datos, y sin preprocesamiento riguroso, la inteligencia artificial se transforma en “Ignorancia automatizada”, la IA no hace magia —hace simulacion predictiva que es basura (garbage in, garbage out).
Y en medio de todo, la medicina no es determinista. la incertidumbre persiste. El dato puede estar completo y limpio, el modelo puede ser robusto, existen múltiples verdades parciales coexistiendo en un mismo paciente; hay variabilidad biológica, subjetividad, contexto. La inferencia clínica requiere integrar múltiples dimensiones —biológicas, psicológicas, sociales— que no siempre caben en un modelo. Y ahí es donde entra la heurística, esas reglas mentales diseñadas con sentido clínico, validadas con evidencia y supervisadas con criterio humano, que los médicos usamos para tomar decisiones en condiciones de presión, con información parcial.
Al usar IA sin comprender esa complejidad, se corre el riesgo de perder la confianza en la ciencia y en la inteligencia artificial aplicada a la salud.
Omitir el anonimato, el consentimiento y la confidencialidad, cruza una línea ética y legal que ningún buen modelo podrá arreglar después. La medicina basada en datos empieza mucho antes del prompt: comienza con el método, porque: “Perder es cuestión de método” y ganar también! En la IA aplicada a salud, un mal método puede costar mucho más que un error estadístico: puede costar confianza, reputación, y en el peor de los casos, vidas humanas.
¿Usas GPT para confirmar lo que ya crees? Entonces no lo estás usando bien…

Uno de los riesgos más importantes que hay en investigación es el de enamorarse de una hipótesis, buscar los métodos para corroborarla a como dé lugar, contraviniendo un de las frases más famosa, “Enamórate del problema, no de la solución” que se atribuye a Uri Levine creador de Waze.
Hoy uno de los peligros más invisibles —pero más frecuentes— al utilizar modelos de lenguaje como GPT, en medicina, es que pueden volverse una herramienta de refuerzo de sesgos cognitivos. De todos ellos, el más común y peligroso es, el sesgo de confirmación: la tendencia a buscar, interpretar y recordar la información que confirma nuestras creencias previas… y a ignorar la que las contradice.
Un ejemplo clásico: un médico sospecha de una patología y consulta GPT para “validar su hipótesis”. Pero si formula el prompt sesgado (”¿Puede X causar Y en pacientes con Z?”), el modelo —que está entrenado para complacer al usuario y completar textos coherentes— probablemente responda afirmativamente y omita contraargumentos, reforzando así una idea que aún no estaba validada por la evidencia. El resultado es una falsa sensación de certeza, no conocimiento real.
Y esto no es trivial, porque la medicina no se hace solo con respuestas bien redactadas, sino con preguntas bien planteadas. Y los buenos clínicos no buscan confirmar sus hipótesis, sino desafiarlas: exploran, descartan, comparan, contrastan.
GPT no razona. No hace inferencias formales ni valida hipótesis. Pero nosotros sí deberíamos hacerlo. Si usamos los LLM como espejos que solo nos devuelven lo que queremos leer, estamos apagando el pensamiento crítico y renunciando a la incertidumbre que acompaña todo acto médico riguroso. Es como la madrastra de Blancanieves: mientras el espejo le respondía lo que ella quería oír, todo estaba bien… pero el día que el espejo le dijo la verdad, la bruja enloqueció.
Peor aún, al hacerlo podríamos estar pasando del uso al abuso: usar la IA para confirmar lo que creemos, y no para abrir nuevas rutas. En lugar de herramienta científica, se vuelve caja de resonancia.
El Espejismo de la Amistad con la IA: Antropomorfización, Peligro y Alucinaciones

La creciente integración de los Modelos de Lenguaje a Gran Escala (LLM) en la práctica médica plantea un desafío importante, la antropomorfización de estas herramientas. La antropomorfización, un proceso por el cual se atribuyen características humanas a entidades no humanas, se manifiesta en el contexto de los LLM cuando los usuarios comienzan a «ver» intenciones, creencias, emociones o conciencia en ellos. Esta tendencia está estrechamente ligada a la psicofantia, que describe la atribución de características psicológicas o mentales a entidades no humanas, lo que puede llevar a una percepción errónea de los LLM como agentes con capacidad de juicio clínico.
Es crucial recordar que, si bien los LLM pueden ser herramientas poderosas para asistir en la práctica médica, no se les debe otorgar un carácter de agente humano. Atribuirles intenciones, creencias o capacidad de juicio es un error que puede llevar a una dependencia excesiva y a la delegación inapropiada de decisiones críticas. Estos modelos funcionan mediante la predicción de la siguiente palabra más probable en una secuencia, careciendo de la comprensión contextual, la experiencia y la intuición que caracterizan el razonamiento clínico humano.
La llamada “empatía artificial” —una característica programada y entrenada en los modelos generativos— puede resultar profundamente confusa para los usuarios humanos. Su tono afable, respuestas personalizadas y estilo conversacional favorecen la antropomorfización y dar lugar a la psicofantía: una confianza ciega e irreflexiva en las respuestas del modelo. Retomando las reflexiones planteadas en una columna previa, La empatía artificial amenaza al humanismo médico. La clave está en recordar que lo que parece humano no necesariamente piensa como un humano.
La confianza excesiva, no hace olvidad que los LLM son propensos a las alucinaciones, entendidas como la generación de información que, aunque pueda ser gramaticalmente correcta y contextualmente apropiada, es falsa o carece de fundamento en la realidad. Algunos prefieren el término «confabulación» para describir este fenómeno, en analogía con el concepto psicológico que se refiere a la producción de recuerdos falsos sin intención de engañar, lo que refleja la idea de que los LLM no «mienten» conscientemente, sino que simplemente generan texto basado en patrones estadísticos. Este riesgo subraya aún más la necesidad del pensamiento crítico y la reflexión por parte del usuario, quien debe evaluar cuidadosamente la información proporcionada por los LLM y validarla con otras fuentes.
La responsabilidad es del que hace el prompt, no todo es prompting

¿De quién es la culpa: del martillo, o del que —creyendo tener destreza— le fractura el dedo al compañero de un solo golpe? Este falso dilema ayuda a entender una verdad incómoda sobre el uso de herramientas de inteligencia artificial, como los modelos de lenguaje: el problema no es el modelo, es el usuario que lo activa sin comprensión, sin preparación y sin medir las consecuencias.
Una de las ilusiones más peligrosas en el uso de herramientas como GPT en el ámbito de la salud es creer que con escribir buenos prompts ya se es experto. Esto es apenas la superficie. El verdadero uso responsable implica entender lo que hay detrás del modelo, sus límites, sus sesgos, y, sobre todo, los riesgos cuando se introducen datos sensibles o mal preparados.
Por ejemplo, muchos profesionales suben hojas de Excel con registros clínicos, creyendo que tienen un “dataset”, cuando en realidad lo que tienen es una lista incompleta y mal curada de observaciones sueltas, campos vacíos, errores tipográficos o y de anonimización, un archivo lleno de atajos en el camino en la cadena de valor del dato clínico para luego preguntarse el por qué de los resultados inconsistentes y sin sentido.
Y hay más: usar modelos de lenguaje para hacer análisis sin preprocesamiento de datos con herramientas de inteligencia artificial apropiadas —como ML no supervisado para limpieza, reducción de dimensionalidad o detección de outliers— es como cocinar sin lavar los ingredientes. Un análisis a partir de datos crudos, mal etiquetados o desbalanceados puede producir fiascos analíticos y decisiones erradas.
Otro caso, es el de “subir imágenes médicas” sin anonimizar, con nombres de pacientes o número de documento u otros datos confidenciales sin autorización de paciente o de la institución, una trangresión ética y legal. No importa cuán “buena” sea la intención o el prompt si el contenido viola principios fundamentales de confidencialidad, protección de datos o consentimiento informado.
La responsabilidad no termina cuando se obtiene una respuesta del modelo. También recae sobre el usuario la obligación de verificar, contrastar y validar la información por otros medios, buscar la fuente, contrastar con literatura científica, consultar con colegas. No es aceptable tomar una salida rápida solo porque “GPT lo dijo”. Ese tipo de lógica automática convierte a un profesional en cómplice de su propio error.
No basta con que “suene bien” o esté redactado con autoridad; si no se verifica, el riesgo de propagar errores o alucinaciones del modelo es altísimo. En medicina, donde cada afirmación puede impactar la vida de una persona, hacer preguntas sin contexto, sin rigor y sin ética, no es un juego de palabras ni una exploración inocente: es una forma irresponsable de ejercer poder informacional.
No basta con saber hablarle al modelo. Hay que saber qué se le puede decir, qué no se le debe dar, y, sobre todo, cómo interpretar lo que devuelve. La responsabilidad va más allá del teclado. No se trata de usar la IA como oráculo, sino como herramienta de apoyo. Y sí, muchos se han quedado en la ilusión de que saber redactar un prompt es equivalente a saber usar IA.
Formular un prompt sin tener clara la estructura del dato, sin entender el proceso clínico detrás, sin anonimizar, sin saber distinguir entre correlación y causalidad, sin verificar lo que se devuelve, es como operar con los ojos vendados y decir que el bisturí es el culpable.

El que hace la pregunta tiene la responsabilidad de verificar la respuesta. Y en salud, esto es aún más crítico. Usar GPT sin juicio clínico ni pensamiento crítico no convierte a nadie en experto; lo convierte en un riesgo para los demás.
Los modelos como Qwen3 y DeepSeek que emplean destilación enfrentan desafíos similares con las alucinaciones, pero con matices distintos a ChatGPT y Claude, pues estos modelos destilados implementan técnicas específicas donde un modelo más pequeño aprende a imitar el comportamiento de uno más grande, priorizando la eficiencia computacional. Esta transferencia de conocimiento puede presentar vulnerabilidades adicionales a las alucinaciones, ya que cualquier tendencia a la confabulación en el modelo maestro puede amplificarse en el estudiante, requiriendo estrategias de mitigación adaptadas como verificación cruzada entre diferentes capas del modelo y métodos de regularización específicos para preservar la fidelidad factual durante el proceso de compresión.
GPT no reemplaza tu juicio clínico, sino se lo delegas
La vida y la medicina se mueven en el campo de la incertidumbre, reglas lógicas, de razonamiento y el conocimiento han intentado otorgar la tranquilidad de la certeza, pero uno de los momentos más críticos en medicina ocurre cuando el profesional se enfrenta a la incertidumbre clínica. Aquí, el razonamiento se activa en múltiples niveles. La práctica médica no se sostiene en verdades absolutas, sino en la constante oscilación entre datos incompletos, experiencia previa y juicio contextual. En este punto, comprender los tres tipos de razonamiento es esencial:
- El deductivo, que parte de una regla general para llegar a una conclusión específica;
- El inductivo, que construye generalizaciones a partir de observaciones particulares; y
- El abductivo, donde, con observaciones incompletas, se infiere la explicación más plausible (aunque no necesariamente cierta).
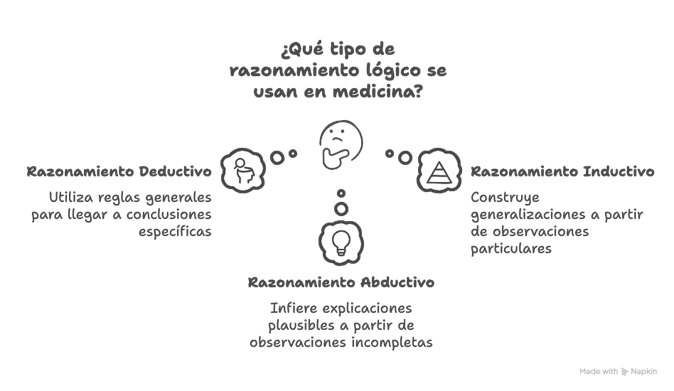
Este último, el razonamiento abductivo, es el más frecuente en el razonamiento clínico, especialmente al formular hipótesis diagnósticas iniciales. Por ejemplo, si un paciente consulta por dolor torácico y tiene factores de riesgo cardiovascular, el médico puede priorizar como más probable un síndrome coronario agudo, aunque no tenga todos los datos aún. Luego, se activan mecanismos inductivos y deductivos conforme se obtienen pruebas y evoluciona el cuadro.
A todo esto, se suma el papel central de las inferencias clínicas, que permiten establecer relaciones de causalidad, asociación o temporalidad entre variables. En medicina, distinguir entre “esto causa aquello” y “esto está asociado con aquello” no es un tecnicismo menor: es la diferencia entre tratar una causa y aliviar una consecuencia.
La inteligencia artificial, especialmente en sus versiones actuales como el aprendizaje automático (ML) y profundo (DL), puede identificar correlaciones con alta precisión, pero tiene serias limitaciones para inferir causalidades y reglas deductivas confiables. Aun cuando se alimenta con grandes volúmenes de datos, sigue siendo vulnerable a sesgos, ruido, omisiones y artefactos contextuales. Su arquitectura se basa en correlaciones, no en comprensión.
Los modelos de lenguaje como GPT no hacen inferencias clínicas con base en contexto real o en conocimiento experiencial, no tienen conciencia, juicio ni contexto clínico real. Su función es predecir la próxima palabra más probable, basada en correlaciones estadísticas. Aunque puedan simular razonamientos, no comprenden la incertidumbre ni el sufrimiento del paciente. No hacen pausa ante lo ambiguo, no desconfían de lo evidente. No ponderan consecuencias éticas.
Y aunque pueden apoyar procesos clínicos, no son una mente médica experta, Este punto nos obliga a reconocer el peligro de delegar decisiones complejas en herramientas que carecen de conciencia situacional. En el pensamiento clínico coexisten los dos sistemas descritos por Kahneman: el sistema 1, rápido e intuitivo, y el sistema 2, lento, deliberativo y analítico. Muchos prompts mal diseñados activan solo el sistema 1 del usuario: aceptan sin cuestionar, copian sin verificar, replican sin digerir. Las LLM pueden convertirse en espejos del sesgo de confirmación: uno les dice lo que quiere oír, y ellas responden con la versión más convincente de esa misma idea, como la fábula del traje del rey que desfilaba desnudó luciendo su última confección, todos le aplaudían la belleza del traje inexistente.
Ningún modelo de lenguaje reemplaza el juicio clínico entrenado. Puede complementarlo, sí, pero nunca suplantarlo. La decisión final debe estar anclada en la responsabilidad profesional y el criterio informado. Quien no entienda esto está usando GPT como quien usa un bisturí sin haber estudiado anatomía.
GPT no reemplaza el juicio clínico ni el juicio experto en ningún ámbito profesional. Puede enriquecerlos al ofrecer alternativas, organizar información o acelerar el acceso a ciertos contenidos, pero también puede confundir si se utiliza sin criterio. Por eso, el pensamiento crítico y analítico del usuario humano, son indispensables. El pensamiento crítico implica cuestionar, contrastar, evaluar la validez de lo que se recibe y no aceptar sin más lo que aparenta ser cierto. El pensamiento analítico, por su parte, permite descomponer un problema complejo en partes manejables para comprender relaciones, estructuras y posibles soluciones. Sin estas capacidades activas en quien consulta, cualquier sistema basado en inteligencia artificial corre el riesgo de ser malinterpretado, sobrevalorado o mal empleado.
No hay excusa para portarse mal
¿Y La gobernanza del uso de modelos LLM y datos en tu institución?
La rápida adopción de modelos de inteligencia artificial generativa como GPT en entornos médicos, académicos y administrativos ha superado, en muchos casos, la capacidad institucional para establecer normas claras de gobernanza. Surge entonces una pregunta fundamental: ¿cómo es la gobernanza para el manejo de los modelos de inteligencia artificial generativa en tu institución? ¿Existe un protocolo que regule su uso? ¿Hay criterios para determinar qué tipo de información puede ingresarse y con qué fines? En muchas organizaciones, la respuesta sigue siendo un silencio incómodo o un gesto de improvisación.
Pero es importante subrayar una premisa ética y legal básica: la ausencia de reglas explícitas no es excusa para la negligencia ni para el mal uso. Así como la ausencia de ley o de autoridad policial no legitima un delito, el desconocimiento o la omisión de marcos regulatorios no justifican el uso irresponsable de tecnologías tan poderosas como los LLM. De hecho, la mayoría de los códigos penales en el mundo son contundentes en este sentido: el desconocimiento de la ley no exime de su cumplimiento.
Y si no lo hay… Si en tu institución aún no existe una regulación, si no hay un comité que esté abordando este tema, si nadie está discutiendo los riesgos y oportunidades de usar modelos como GPT en salud, ¿por qué no lo inicias tú? Tal vez el cambio empieza con una conversación, una alerta o una propuesta. Porque si ya estás usando estas herramientas o viendo cómo otros las usan sin criterios, eres testigo directo de una transformación que requiere liderazgo responsable y proactivo. La ética en inteligencia artificial no es una tarea delegable ni un lujo futurista: es una responsabilidad presente.
En este contexto, vale la pena preguntarse: ¿se pueden exportar elementos del marco legal del Habeas Data colombiano al uso de modelos como GPT? La respuesta es sí, y no solo es posible, sino deseable. El Habeas Data, entendido como el derecho fundamental a conocer, actualizar y rectificar la información personal que repose en bases de datos, implica principios de finalidad, necesidad, veracidad, seguridad y confidencialidad. Todos ellos aplican —y deberían exigirse— cuando se interactúa con modelos de IA a los que se les alimenta con información sensible, identificable o clínicamente relevante. La cantidad, el tipo y el contexto del dato compartido deben ser evaluados con el mismo rigor con que se protege la historia clínica de un paciente.
Por tanto, no hay excusa válida para usar estas herramientas sin un marco ético y jurídico. La responsabilidad individual y colectiva es ineludible, y el compromiso institucional con la protección de datos y la calidad del uso de IA no puede postergarse más. La gobernanza no es opcional.
Conclusión – el buen uso
Este debate no es nuevo. Desde los años 70, con sistemas como INTERNIST-1 y MYCIN, se intentó representar el conocimiento médico mediante reglas lógicas estructuradas. La promesa de estos sistemas era clara: si se definían correctamente las reglas y sus condiciones, se podía simular razonamiento experto. Sin embargo, este enfoque pronto chocó con los límites de la escalabilidad y la complejidad de lo clínico. Los enfoques actuales, basados en machine learning (ML) y deep learning (DL), abandonaron esa lógica estructurada para abrazar la estadística en gran escala. Pero al hacerlo, perdieron capacidad explicativa y sacrificaron interpretabilidad.
Hoy, con los LLM y la arquitectura de agentes autónomos, se empieza a vislumbrar una posibilidad de integrar lo mejor de ambos mundos: sistemas capaces de manejar grandes volúmenes de datos, generar lenguaje natural coherente y, eventualmente, combinarlo con reglas explícitas de deducción, surge un reto, quienes creen que ya dominan el uso de modelos de lenguaje porque han aprendido a diseñar prompts efectivos corren el riesgo de simplificar un fenómeno complejo. El diseño del prompt es solo la puerta de entrada. Lo que sigue es más exigente: verificar, contrastar, analizar, contextualizar, corregir. Y, sobre todo, responsabilizarse.
La inteligencia artificial generativa no es magia. Es una herramienta. Y como toda herramienta, no tiene intenciones ni ética propias. No decide a quién daña ni a quién ayuda. Eso depende de quién la usa, cómo la usa, para qué la usa, y con qué grado de conciencia sobre sus limitaciones.
Esta convergencia se acerca al ideal de una IA más robusta y confiable, quizás un primer paso hacia la IA general. Pero mientras esa promesa madura, debemos aprender a usar correctamente las herramientas que ya tenemos.
Porque la diferencia entre aprovechar una herramienta poderosa y hacer un desastre con ella… es cuestión de método.
Planteamos la pregunta ¿Pero la ética debe enfocarse en los algoritmos y herramientas de IA (la máquina), o en los diseñadores, investigadores e implementadores de la IA (los humanos)? (https://aipocrates.blog/2025/01/19/inteligencia-artificial-en-2025-como-el-personal-sanitario-puede-utilizarla-desde-ya-en-su-dia-a-dia/)
