Rafael Brango. Miembro Fundador de AIpocrates
Walberto Buelvas. Director Médico Funcentra. Miembro Fundador de AIpocrates
Damos continuidad retomando el último párrafo de nuestra columna anterior (https://aipocrates.blog/2025/04/20/la-diabetes-y-la-hipertension-como-se-relacionan-con-el-machine-learning-parte-1/). El uso de modelos de ML, como los de Oikonomou y Khera, permite la creación de modelos predictivos para el cuidado personalizado, mejorando el diagnóstico, pronóstico y tratamiento de la diabetes y sus complicaciones cardiovasculares, estos modelos facilitan la detección de pacientes de alto riesgo y resaltan las relaciones no lineales entre factores clave como la duración del sueño nocturno,
los niveles de triglicéridos y la circunferencia de la cintura, y el riesgo de ECV. Además, el análisis de los valores de SHAP revela la importancia de ciertas características en la predicción de eventos de ECV, como la duración del sueño, los niveles de triglicéridos y la circunferencia de la cintura [12]. SHAP mejora la transparencia e interpretabilidad de los modelos de aprendizaje automático en el
ámbito de la salud, lo cual es crucial para comprender el proceso de toma de decisiones del modelo y para generar confianza en su aplicación clínica (https://www.youtube.com/watch?v=L8_sVRhBDLU).
La Figura 2 muestra las 20 características más importantes utilizadas en el análisis predictivo del estudio, ordenadas según su relevancia. En el gráfico, cada punto representa una muestra, con los colores indicando la magnitud del valor de la característica (rojo para valores altos, azul para bajos). El eje vertical lista las características de mayor a menor importancia, y el eje horizontal muestra los valores SHAP, los cuales reflejan cómo cada característica influye en la predicción: valores SHAP positivos aumentan la probabilidad de un resultado positivo (cercano a 1), y negativos la disminuyen (cercano a 0). La característica más influyente es la edad, donde a mayor edad se asocia una mayor probabilidad de una predicción positiva. Le siguen factores geográficos, como la provincia y el tipo de zona (rural o urbana). También se identifican variables relacionadas con la salud corporal, como la circunferencia de la cintura, el índice de masa corporal (IMC) y la relación cintura-cadera (RCC), en donde valores más altos aumentan la probabilidad de diagnóstico positivo. Por el contrario, condiciones socioeconómicas como el desempleo y bajo nivel educativo se asocian con una mayor probabilidad de un resultado positivo, indicando una relación inversa con estas variables. [12]
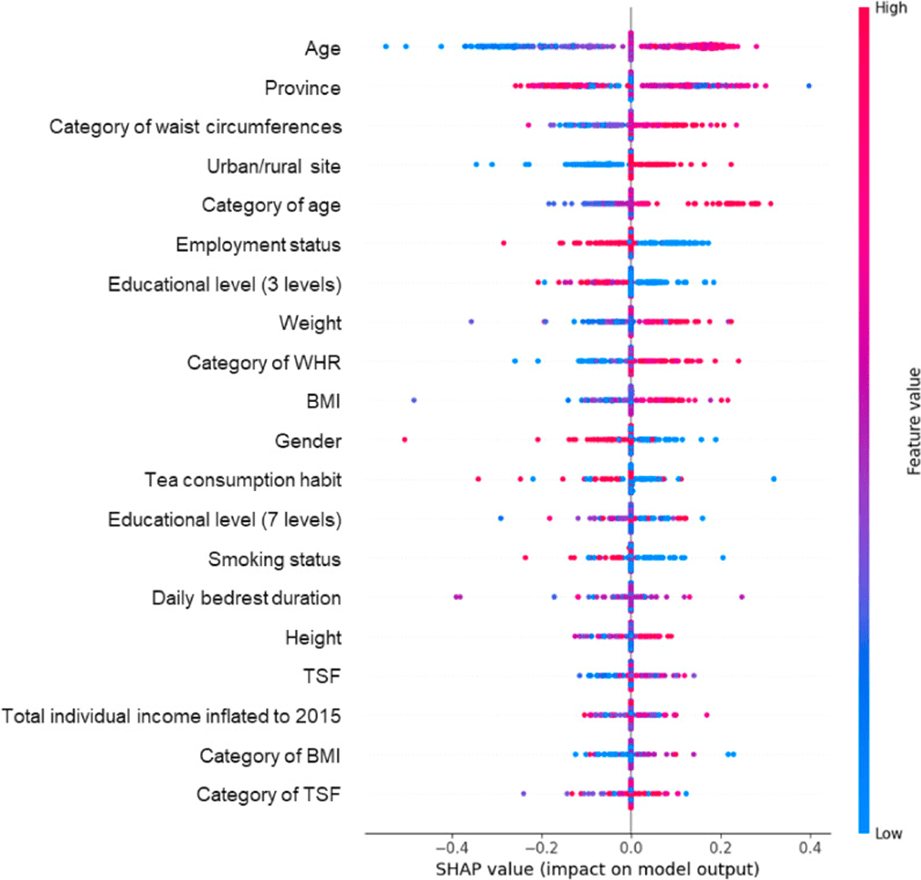
Fig No. 2 Valores SHAP en el modelo AMFormer. Muestra la importancia de la predicción del modelo de 29 características AMFormer, destacando los valores SHAP de las 20 características más importantes. (https://pmc.ncbi.nlm.nih.gov/articles/PMC11744027/)
En el ámbito médico, SHAP se ha convertido en una herramienta valiosa para interpretar modelos de machine learning aplicados al diagnóstico, pronóstico y toma de decisiones clínicas. Sus beneficios incluyen la capacidad de explicar de forma consistente cómo cada variable clínica (como edad, presión arterial, resultados de laboratorio o antecedentes médicos) influye en la predicción de un modelo, lo cual es crucial para generar confianza entre los profesionales de la salud. También SHAP permite interpretar modelos complejos como redes neuronales o algoritmos de ensamble, que de otro modo serían difíciles de entender, facilitando su adopción en entornos clínicos. es versátil, aplicable en diversas áreas médicas, desde la predicción de enfermedades cardiovasculares hasta la detección temprana de cáncer[13]. Interpretar los valores SHAP en escenarios clínicos complejos requiere formación técnica específica, lo que podría representar una barrera para su implementación en equipos médicos sin formación en inteligencia artificial. Aun así, su potencial para mejorar la transparencia y confianza en los sistemas de apoyo clínico lo convierte en una herramienta prometedora para la medicina basada en datos. [14]
Las gráficas presentadas en los Anexos 1 y 2 corresponden a indicadores clave del tablero de gestión clínica de MediSinú IPS, enfocados en pacientes con diabetes e hipertensión. El Anexo 1 muestra la caracterización general de 64.950 pacientes, incluyendo distribución por patologías, sexo, clasificación del estadio renal e índice de masa corporal (IMC). Se evidencia una alta proporción de usuarios en estadios tempranos de enfermedad renal crónica y una prevalencia significativa de obesidad. El Anexo 2 detalla la subclasificación de 4.945 pacientes con enfermedad cardiovascular (ECV), con énfasis en metas de LDL, HDL y riesgo según Framingham. Se observa que una parte considerable no alcanza las metas óptimas de lípidos, lo cual resalta áreas de mejora para intervenciones clínicas personalizadas. Estos tableros permiten un enfoque analítico y predictivo para la toma de decisiones clínicas, alineado con modelos de machine learning descritos en el artículo principal.
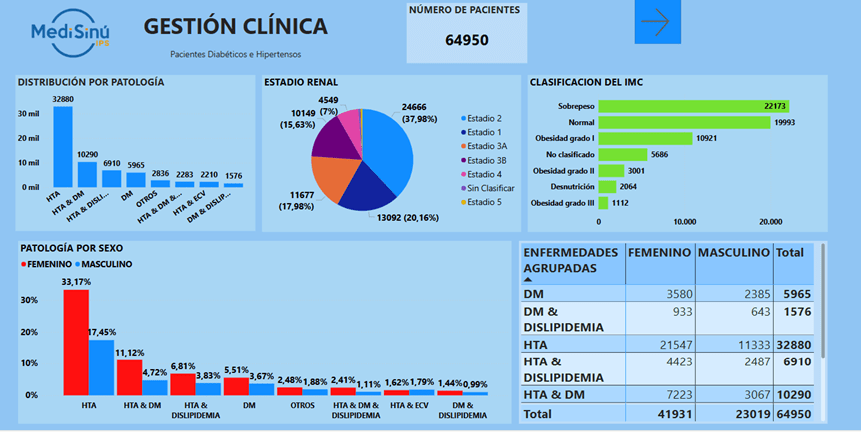
Anexo 1. Página Principal de caracterización del tablero
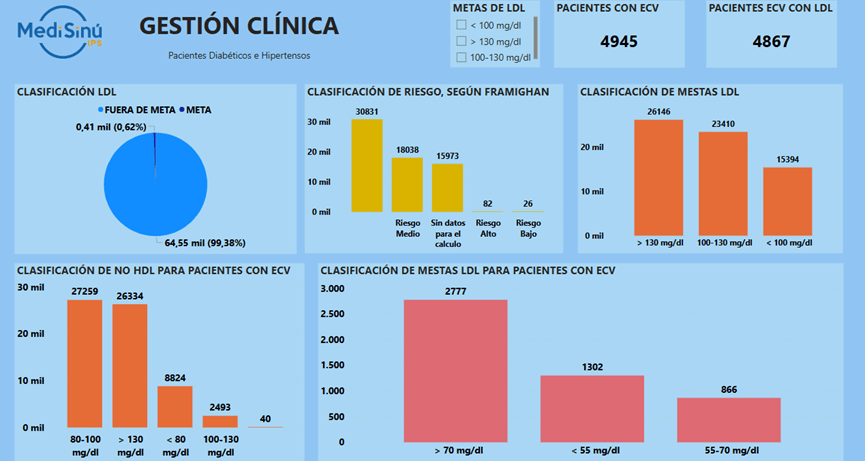
Anexo 2. Indicadores clínicos para gestión en el tablero con subclasificación de usuarios con ECV
En el análisis de datos del China Health and Retirement Longitudinal Study (CHARLS), los algoritmos de ML revelaron relaciones no lineales entre factores como la duración del sueño nocturno, los niveles de triglicéridos y la circunferencia de la cintura y el riesgo de ECV. De manera similar, en el análisis de datos del National Health and Nutrition Examination Survey (NHANES), los modelos de ML identificaron contribuyentes clave a la predicción de ECV, como incidentes relacionados con el alcohol y atributos dietéticos. Estos hallazgos resaltan el potencial del ML para descubrir patrones complejos y mejorar la predicción de CVD.
Aplicaciones Actuales y Cribado, de la regresión lineal al análisis de múltiples variables
Las guías actuales recomiendan la evaluación informal de factores de riesgo o calculadoras de riesgo validadas con una precisión moderada, esto ha llevado a la exploración de herramientas basadas en ML con datos estructurados y no estructurados para mejorar la detección temprana y estratificación de riesgo de prediabetes y diabetes en adultos asintomáticos. Los desarrollos han generado puntajes de riesgo basados en ML y se han propuesto para una evaluación más personalizada del riesgo de diabetes tipo 2 [3].
El Centro Nacional de Investigaciones Cardiovasculares (CNIC) y el Banco Santander han desarrollado un algoritmo basado en ML llamado EN-PESA, este modelo utiliza variables como la edad, tensión arterial, dieta y marcadores medibles en análisis de sangre y orina, que son fácilmente medibles en atención primaria, para ofrecer una predicción individualizada y fiable del riesgo de padecer enfermedades cardiovasculares, específicamente la enfermedad aterosclerótica. Se ha demostrado que mejora la eficacia de las pautas tradicionales de riesgo cardiovascular [1].
Se están desarrollando soluciones habilitadas por IA que utilizan el ECG (de 12 derivaciones o de una sola derivación) para detectar formas subclínicas de cardiomiopatía y arritmias. El uso de ECG e imágenes cardiacas en investigaciones recientes han expandido los enfoques hacia el dispositivo portátil, lo que permite la escalabilidad en entornos de bajos recursos. Un estudio también destaca el uso de resonancia magnética cardíaca habilitada por IA para el cribado y diagnóstico de ECV. [3].
Avances Recientes en Modelos Predictivos
Superioridad de modelos ML sobre modelos estadísticos tradicionales, particularmente random forest y aprendizaje profundo, en una revisión sistemática y metaanálisis reciente encontró que los modelos de ML que utilizan registros médicos electrónicos (EHR), demostraron un rendimiento superior en la predicción de riesgo de ECV a mediano y largo plazo (5-10 años) en comparación con los puntajes de riesgo convencionales como QRISK3 y ASCVD [7].
Uso de datos de EHR a gran escala: Se están llevando a cabo iniciativas como LEGEND-T2DM para realizar análisis de efectividad comparativa utilizando grandes bases de datos multinacionales del mundo real a través de enfoques tradicionales y de big data impulsados por ML [3].
Combinación de diferentes tipos de datos: Los modelos de ML están utilizando diversas fuentes de datos simultáneamente para mejorar la predicción. Por ejemplo, un estudio demostró que la inclusión de resultados de laboratorio aumentó sustancialmente las capacidades predictivas para la detección de diabetes. Otro estudio utilizó datos de encuestas de salud (BRFSS) para predecir el riesgo de enfermedad cardíaca [2, 8].
Algoritmos específicos y su rendimiento
Se han evaluado varios algoritmos de ML para la predicción de ECV, incluyendo REP Tree, M5P Tree, Random Tree y regresión lineal. Un estudio reciente incluso reportó una precisión del 100% con el modelo Random Tree en la predicción del riesgo cardiovascular. Otros algoritmos como XGBoost han mostrado un rendimiento sobresaliente en la predicción de enfermedades del sistema circulatorio utilizando datos de rutina [2, 9].
Educación en Inteligencia Artificial para Pacientes
La educación en IA dirigida a pacientes tiene como propósito empoderarlos con conocimientos básicos sobre cómo esta tecnología se integra en la atención médica, comprender los principios fundamentales de la IA permite a los pacientes aprovechar de forma más consciente y efectiva las herramientas que apoyan su diagnóstico y tratamiento. [11].
Este entendimiento promueve una participación más activa en la toma de decisiones sobre su salud, fortaleciendo la relación médico-paciente. Informar a los pacientes sobre cómo se toman decisiones apoyadas en IA, qué datos se analizan y con qué propósito, contribuye a una percepción más positiva y segura de estas herramientas.
Involucrar a los pacientes desde las fases tempranas del desarrollo de tecnologías basadas en IA escuchando sus necesidades y percepciones puede no solo mejorar la utilidad de estas herramientas, sino también reforzar la integridad y la benevolencia percibida de los profesionales de la salud. Una IA más humana empieza por un paciente más informado.
En conclusión
El aprendizaje automático está revolucionando la predicción y el manejo de las enfermedades cardiovasculares al mejorar la detección temprana, personalizar evaluaciones de riesgo y optimizar estrategias terapéuticas. A medida que estas tecnologías continúan evolucionando, su integración en la práctica clínica podría marcar una diferencia significativa en la prevención de ECV y la mejora de los resultados en salud.
Cada dato clínico es un grano de arena cayendo. La enfermedad no espera. Pero si logramos voltear el reloj a tiempo con inteligencia artificial, podemos transformar segundos en años, diagnósticos en oportunidades. La medicina del futuro no es ciencia ficción: es saber cuándo actuar. Y ese cuándo… es ahora.
Se utilizo chat gpt para parafrasear algunos párrafos
Bibliografía
- Machine learning para mejorar la predicción de las enfermedades cardiovasculares https://pro.campus.sanofi/es/dislipemia/articulos/machine-learning-prediccion-enfermedades-cardiovasculares
- Modelos de Machine Learning para Predicción de Riesgo Cardíaco https://campushealthtech.com/blog-alumno/modelos-de-machine-learning-para-prediccion-de-riesgo-cardiaco/
- Machine learning in precision diabetes care and cardiovascular risk prediction. Cardiovasc Diabetol. 2023 Sep 25;22(1):259. doi: 10.1186/s12933-023-01985-3. PMID: 37749579; PMCID: PMC10521578. https://pmc.ncbi.nlm.nih.gov/articles/PMC10521578/
- JACC: Investigadores del CNIC diseñan un algoritmo que personaliza el riesgo cardiovascular en personas sanas. Centro Nacional de Investigaciones Cardiovasculares. 29 de septiembre de 2020. [Citado en…]. Disponible en: https://www.cnic.es/es/noticias/jacc-investigadores-cnic-disenan-un-algoritmo-que-personaliza-riesgo-cardiovascular
- Enfermedades cardiovasculares https://www.who.int/es/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds)
- Characterisation of cardiovascular disease (CVD) incidence and machine learning risk prediction in middle-aged and elderly populations: data from the China health and retirement longitudinal study (CHARLS) https://pmc.ncbi.nlm.nih.gov/articles/PMC11806717/
- Machine learning based prediction models for cardiovascular disease risk using electronic health records data: systematic review and meta-analysis https://pmc.ncbi.nlm.nih.gov/articles/PMC11750195/
- Dinh A, Miertschin S, Young A, Mohanty SD. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med Inform Decis Mak. 2019 Nov 6;19(1):211. doi: 10.1186/s12911-019-0918-5. PMID: 31694707; PMCID: PMC6836338. https://pmc.ncbi.nlm.nih.gov/articles/PMC6836338/
- Wang Z, Gu Y, Huang L, Liu S, Chen Q, Yang Y, Hong G, Ning W. Construction of machine learning diagnostic models for cardiovascular pan-disease based on blood routine and biochemical detection data. Cardiovasc Diabetol. 2024 Sep 28;23(1):351. doi: 10.1186/s12933-024-02439-0. PMID: 39342281; PMCID: PMC11439295. https://pmc.ncbi.nlm.nih.gov/articles/PMC11439295/
- American Heart Association. Cardiovascular-Kidney-Metabolic Health: A Presidential Advisory From the American Heart Association. Circulation. 2023;148:1606–1635. DOI: 10.1161/CIR.0000000000001184.
- Aplicaciones de la inteligencia artificial en la educación médica: una revisión sistemática https://pmc.ncbi.nlm.nih.gov/articles/PMC11872247/
- Application of machine learning algorithms in predicting new onset hypertension: a study based on the China Health and Nutrition Survey https://pmc.ncbi.nlm.nih.gov/articles/PMC11744027/
- ¿Qué es SHAP? Explicación clara para modelos de IA https://delatorre.ai/que-es-shap-explicacion-clara-para-modelos-de-ia/
- Bienvenido a la documentación de SHAP https://shap.readthedocs.io/en/latest/
- Machine Learning in Medicine https://pmc.ncbi.nlm.nih.gov/articles/PMC5831252/
- Métodos Estadísticos Tradicionales https://fastercapital.com/es/palabra-clave/m%C3%A9todos-estad%C3%ADsticos-tradicionales.html
