Autora: Andrea Rincón G. Médica Familiar. MSc Salud Pública. M.Sc.(c) Big Data Sanitario. Miembro
Tanque de Pensamiento AIpocrates

La inteligencia artificial (IA) está experimentando un crecimiento sin precedentes en el
ámbito sanitario, consolidándose como una herramienta clave para el desarrollo de
sistemas de información y la mejora en la toma de decisiones clínicas. Si bien estas
tecnologías prometen optimizar la atención médica y fortalecer la salud pública, también
generan una creciente preocupación por su potencial para perpetuar e incluso agravar
desigualdades preexistentes. Esto puede comprometer el rendimiento de los modelos y
limitar los beneficios esperados, especialmente en determinados grupos de pacientes (1).
En el contexto de la IA, el sesgo no es un fenómeno accidental, puede surgir en cualquier
etapa del ciclo de vida de un modelo, desde el diseño y la recolección de datos hasta la
elección del algoritmo, su validación, implementación y difusión de resultados.
GIGO: Garbage In, Garbage Out y el mito de los datos “neutrales”
Un principio fundamental en ciencia de datos es GIGO (Garbage In, Garbage Out): si los
datos de entrada son defectuosos, incompletos o sesgados, los resultados del sistema
reflejarán esas mismas deficiencias. En inteligencia artificial médica, esto adquiere una
relevancia crítica. Los sistemas de toma de decisiones impulsados por IA, no solo están
expuestos a sesgos, sino que pueden reproducirlos e incluso amplificarlos (2,3).
No se trata de simples errores técnicos corregibles, sino de mecanismos que, al
implementarse sin un análisis crítico de sus fundamentos y contextos, pueden reforzar
desigualdades estructurales. En entornos clínicos, estas distorsiones tienen consecuencias
reales, en especial cuando un modelo sesgado puede conducir a diagnósticos erróneos,
tratamientos inadecuados y resultados en salud desiguales (4).
¿De dónde vienen los sesgos?
El sesgo puede producirse por múltiples causas, entre ellas, el uso de datos de
entrenamiento no representativos (por ejemplo, con pacientes de un solo grupo étnico, edad
o región), decisiones de diseño del modelo que prioriza ciertas variables sobre otras sin
justificación clínica, o la omisión de contextos clínicos, sociales o éticos relevantes para la
interpretación de los datos (4).
Para abordar este problema de forma sistemática, es fundamental comprender cómo y en
qué etapas del desarrollo de la IA pueden surgir estos sesgos. A continuación, se intenta
describir la anatomía general de un sesgo, identificando sus principales tipos y las fases en
las que tienden a aparecer (2-5).
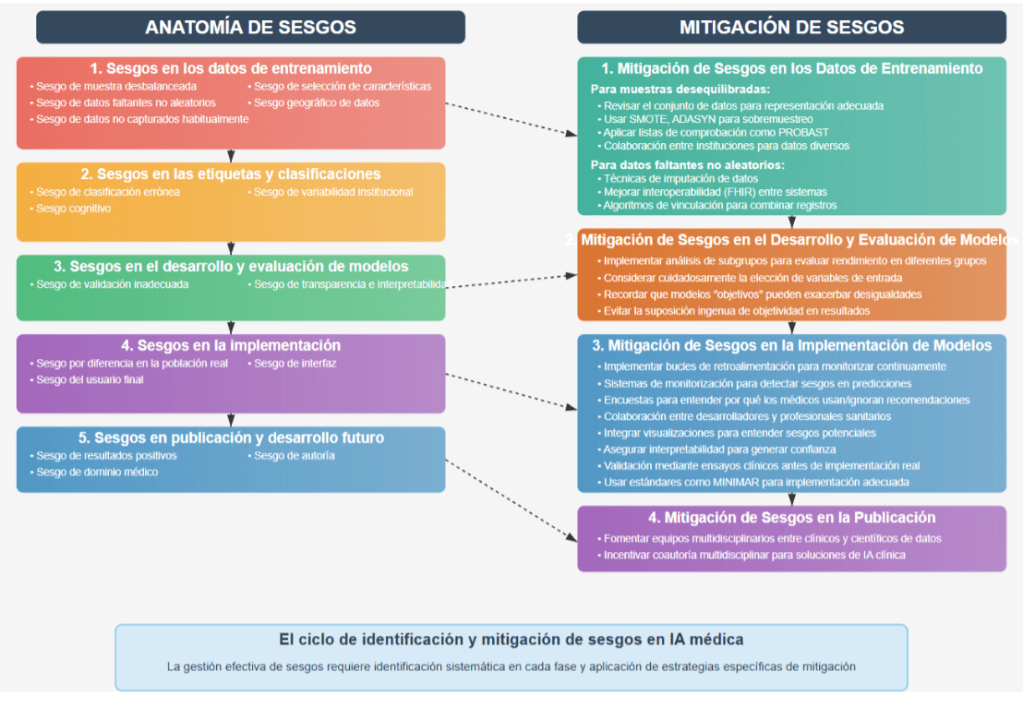
Anatomía de un sesgo
El sesgo en la IA médica comienza con los datos, pero no termina ahí. Comprender en qué
momento ocurre cada tipo de sesgo es clave para diseñar estrategias de mitigación
efectivas. La siguiente clasificación, basada en evidencia científica disponible, busca facilitar
la identificación de estos sesgos y orientar el desarrollo de estrategias para mitigarlos (2-5)
| Sesgos en los datos de entrenamiento ● Sesgo de muestra desbalanceada (subrepresentación) : Conjuntos de datos que excluyen o incluyen de forma insuficiente a ciertos grupos (p. ej., pacientes no caucásicos), lo que limita la generalización del modelo. ● Sesgo de datos faltantes no aleatorios:Ausencias sistemáticas de información (como pruebas no realizadas o diagnósticos no registrados) que afectan a ciertos grupos y distorsionan los resultados.Estás ausencias de datos pueden inducir un comportamiento sesgado del modelo, llevando a una estimación del riesgo inadecuada. ● Sesgo de datos no capturados habitualmente: Información relevante que no suele registrarse en los sistemas sanitarios, como determinantes sociales de la salud. ● Sesgo de selección de características: Elección inadecuada de variables para entrenar modelos, excluyendo factores predictivos importantes para ciertos segmentos de la población. ● Sesgo geográfico de datos: Datos usados provenientes de países como EE.UU. que limita su generalización global. |
| Sesgos en las etiquetas y clasificaciones ● Sesgo de clasificación errónea: Errores sistemáticos en la asignación de categorías clínicas, influenciados por características del paciente o por prácticas locales. Este tipo de sesgo puede reflejar sesgos cognitivos implícitos de los profesionales de salud. ● Sesgo cognitivo: Prejuicios inconscientes de los profesionales que etiquetan los datos que luego entrenan los algoritmos, perpetuando patrones de diagnóstico o tratamiento inadecuados. ● Sesgo de variabilidad institucional: Variabilidad en las prácticas entre centros de salud que impacta cómo se generan las etiquetas y se entrenan los modelos. |
| Sesgos en el desarrollo y evaluación de modelos ● Sesgo de validación inadecuada: Evaluación insuficiente del modelo en poblaciones diversas o en entornos clínicos diferentes a los de entrenamiento. ● Sesgo de transparencia e interpretabilidad: Modelos de “caja negra” que impiden entender cómo y por qué se toman ciertas decisiones para distintos grupos. |
| Sesgos en la implementación ● Sesgo por diferencia en la población real: Discrepancias entre la población de entrenamiento y la real donde se aplica el modelo. ● Sesgo del usuario final:Variaciones en cómo los profesionales interpretan, aceptan o descartan las recomendaciones del modelo según el paciente. ● Sesgo de interfaz: Interfaces mal diseñadas o requerimientos complejos que dificultan su adopción equitativa. |
| Sesgos en publicación y desarrollo futuro ● Sesgo de resultados positivos: Tendencia a publicar sólo estudios con resultados positivos o modelos con rendimiento superior, distorsionando la visión del panorama completo. ● Sesgo de dominio médico: Sobrerrepresentación de ciertas especialidades médicas como radiología y oncología. ● Sesgo de autoría: Predominio de autores masculinos y expertos en datos, en detrimento de profesionales clínicos e investigadoras femeninas. |
Tabla 1. Realización propia
Casos relevantes de sesgos en IA en contextos clínicos.
Los siguientes casos ilustran cómo los sesgos pueden surgir en distintas etapas del ciclo de
vida de la inteligencia artificial, afectando negativamente la equidad y la calidad de la
atención clínica(4,5)
● Epic Sepsis Model (ESM)
El Epic Sepsis Model fue desarrollado utilizando datos de la historia clínica electrónica con
el objetivo de generar alertas automáticas a los médicos sobre pacientes que podrían estar
desarrollando sepsis.Sin embargo, estudios posteriores a su implementación en el mundo
real revelaron que su rendimiento fue significativamente inferior de lo que se había
informado inicialmente.Se encontró que el ESM omitía dos tercios de los casos de sepsis y,
al mismo tiempo, emitía falsas alarmas con frecuencia. La cohorte de pacientes utilizada
para entrenar y validar el modelo original puede haber diferido significativamente de la
población de pacientes a la que se aplicó posteriormente en el mundo real. Estas
diferencias pueden incluir variaciones en la composición demográfica u otras características
relevantes (3,4)
● Algoritmo de asignación de recursos sanitarios
Un sistema diseñado para priorizar el acceso a camas de urgencias utilizaba como criterio
principal antecedentes médicos codificados mediante CIE-10 en la historia clínica
electrónica. Sin embargo, esta estrategia generó resultados sesgados, pacientes de nivel
socioeconómico bajo, con historias clínicas fragmentadas o con menor número de consultas
previas en el sistema de salud, eran clasificados incorrectamente como de bajo riesgo. La
falta de información, lo cual puede ser producto de barreras estructurales para acceder a
servicios de salud llevó a una subestimación del riesgo clínico real y, en consecuencia, a
una priorización inadecuada. Este caso evidencia cómo la dependencia de datos
codificados, sin considerar su contexto de origen ni su calidad, puede reforzar inequidades
existentes y excluir a poblaciones vulnerables de una atención oportuna y adecuada (4,5)
● Detección de melanoma mediante IA
Los modelos entrenados principalmente con imágenes de piel clara (mayoritariamente de
bases de datos de EE.UU., Europa y Australia) mostraron un rendimiento significativamente
inferior para imágenes de lesiones en tonos de piel más oscuros. Esto se traduce en una
menor capacidad de predicción cuando se utilizan en el mundo real para diagnosticar
melanomas en pacientes con piel más oscura. Aunque la incidencia del melanoma es más
común en individuos blancos no hispanos y puede presentarse de manera diferente en
pieles oscuras, esto no justifica la exclusión de estos grupos de pacientes de los beneficios
de la detección de melanoma basada en IA. Este caso muestra cómo los desbalances en
los datos de entrenamiento pueden llevar a disparidades en la precisión diagnóstica,
especialmente crítico en condiciones donde la detección temprana impacta directamente en
la supervivencia(1,4)
● Predicción de mortalidad hospitalaria (MIMIC-III)
Un estudio basado en el conjunto de datos MIMIC-III, una base de datos clínica de código
abierto que recoge información de pacientes ingresados en unidades de cuidados intensivos
en hospitales de EE.UU. entrenó un modelo para predecir mortalidad intrahospitalaria.
Aunque este conjunto es ampliamente utilizado en la investigación médica, refleja
desigualdades estructurales presentes en el sistema de salud.El análisis reveló que la
representación desequilibrada de grupos raciales tuvo un impacto significativo en el
rendimiento del modelo, especialmente al utilizar marcadores clínicos como la creatinina
para evaluar deterioro de la función renal. Los resultados mostraron que las mujeres no
blancas presentaban un 35,06% más de deterioro en los niveles de creatinina al momento
de recibir intervención, en comparación con mujeres blancas; en los hombres no blancos, el
deterioro fue un 19,94% mayor que en hombres blancos.Estos hallazgos sugieren que
pacientes no blancos llegaban a un estado clínico más avanzado antes de recibir atención
médica crítica, lo que podría reflejar barreras de acceso, sesgos implícitos en los procesos
de decisión clínica o decisiones no equitativas en los momentos de intervenciones médicas.
Este caso evidencia cómo los modelos de IA no solo pueden replicar inequidades
existentes, sino también enmascararlas bajo métricas aparentemente objetivas, si no se
analizan críticamente las condiciones bajo las cuales se generaron y aplicaron los datos
(2,4)
● Disparidades de género en admisiones a UCI (HiRID)
El conjunto de datos HiRID, una base abierta de cuidados intensivos generada a partir de
más de 33.000 ingresos en la UCI del Hospital Universitario de Berna, Suiza (2008–2016),
se ha utilizado para desarrollar y validar modelos de inteligencia artificial en contextos
clínicos. Al analizar surgieron evidencias de disparidades de género en el acceso a
cuidados intensivos.Los datos mostraron que las mujeres ingresaban a la UCI con un
estado clínico significativamente más deteriorado que los hombres, especialmente en
parámetros como la creatinina y las enzimas hepáticas. Específicamente, al momento de
admisión, las mujeres presentaban un 33,7% más de deterioro en los niveles mínimos de
creatinina y un 9,3% más de deterioro en los niveles máximos de ALT, en comparación con
los hombres.Estos resultados sugieren que las mujeres debían estar en condiciones clínicas
más críticas que los hombres para recibir el mismo nivel de atención médica. Este hallazgo
es especialmente preocupante porque indica que, incluso en sistemas de salud con acceso
universal, los algoritmos y decisiones clínicas pueden estar influenciados por sesgos
estructurales o implícitos. Así, la IA no solo refleja desigualdades previas, sino que corre el
riesgo de consolidarlas si no se diseñan mecanismos explícitos para mitigar estas brechas
(2,4,5).
Estrategias de mitigación de sesgos en IA médica
Los investigadores destacan la importancia de identificar y abordar los sesgos en los
modelos de inteligencia artificial. Por ello, es fundamental aplicar estrategias de evaluación
crítica antes de confiar ciegamente en un modelo que será utilizado en la práctica clínica.
Validaciones externas, auditorías éticas, análisis de equidad y pruebas en entornos reales
son algunas de las medidas necesarias para garantizar que el modelo no perpetúe ni
amplifique inequidades existentes (2-6).
| 1. Mitigación de Sesgos en los Datos de Entrenamiento |
| Tamaños de muestra desequilibrados o Subrepresentación ● Revisar y caracterizar exhaustivamente el conjunto de datos para asegurar una representación adecuada de todas las dimensiones raciales, étnicas y sociodemográficas. ● Emplear métodos estadísticos durante el preprocesamiento de datos para abordar el desequilibrio, como el sobremuestreo utilizando técnicas como SMOTE (Técnica de Sobremuestreo Sintético de Minorías) y ADASYN (Muestreo Sintético Adaptativo). ● Aplicar listas de comprobación estandarizadas para la presentación de informes, como PROBAST, para evaluar el riesgo de sesgos en datos desequilibrados. ● Cultivar conjuntos de datos grandes y diversos mediante la colaboración entre instituciones y países para representar mejor las variaciones dentro y entre los grupos de pacientes. |
| Datos faltantes no aleatorios ● Aplicar técnicas de imputación de datos para rellenar los valores faltantes con valores probables basados en pacientes similares ● Fortalecer los protocolos de intercambio de datos y mejorar la interoperabilidad entre los sistemas de registros de salud. Iniciativas como FHIR son fundamentales para esto. ● Utilizar algoritmos probabilísticos de vinculación de registros para combinar registros de pacientes entre diferentes sistemas sanitarios. ● Diseñar interfaces de usuario que resalten los datos faltantes para los médicos, fomentando la introducción de datos más completos. |
| Datos no capturados típicamente ( DSS determinantes sociales de la salud) ● Utilizar instrumentos de recogida de datos estandarizados y fáciles de usar, como cuestionarios estructurados o encuestas de tamizaje, para cuantificar los DSS e incorporarlos a las historias clínicas electrónicas y a los flujos de trabajo clínicos. ● Emplear métodos basados en el procesamiento del lenguaje natural, para recopilar información sobre DSS a partir de notas clínicas no estructuradas y relatos de pacientes |
| 2. Mitigación de Sesgos en el Desarrollo y la Evaluación de Modelos ● Implementar el análisis de subgrupos para evaluar el rendimiento del modelo en diferentes grupos de pacientes. ● Considerar cuidadosamente cómo la elección de las variables de entrada puede influir en la aparición de sesgos. ● Ser consciente de que incluso modelos aparentemente objetivos pueden exacerbar desigualdades. ● Los desarrolladores deben evitar la suposición ingenua de objetividad en los resultados del modelo. |
| 3. Mitigación de Sesgos en la Implementación de Modelos ● Implementar bucles de retroalimentación adecuados que puedan supervisar y verificar continuamente los resultados y el rendimiento del modelo en entornos clínicos ● Utilizar sistemas de monitorización continua para detectar y cuantificar los sesgos en las predicciones de los modelos. ● Implementar infraestructuras de retroalimentación (por ejemplo, encuestas) para comprender por qué los médicos utilizan o ignoran las recomendaciones de la IA. ● Los desarrolladores deben trabajar en conjunto con los responsables de los hospitales y los profesionales sanitarios para alinear la implementación del modelo con las demandas del flujo de trabajo clínico. ● Integrar tableros de control, visualizaciones o notificaciones que ayuden a los médicos a comprender los posibles sesgos en las decisiones asistidas por IA. ● Asegurar la interpretabilidad de la IA para generar confianza en los médicos y facilitar la adopción. ● Realizar una validación rigurosa a través de ensayos clínicos antes de la implementación en el mundo real para demostrar una aplicación no sesgada ● El uso de estándares como MINIMAR (Minimum Information for Medical AI Reporting), aplicable en distintas fases del proceso de mitigación de sesgos, puede servir como guía para una implementación adecuada de modelos de IA en entornos clínicos reales |
| 4.Mitigación de Sesgos en la Publicación: ● Fomentar la formación de equipos de investigación en IA con colaboraciones multidisciplinarias entre clínicos y científicos de datos ● Las revistas y los organismos de financiación podrían fomentar e incentivar la coautoría multidisciplinar para estudios que desarrollen soluciones de IA para uso clínico, especialmente en áreas pobremente representadas. |
Tabla 2. Realización propia.
La siguiente visualización proporciona un resumen académico orientado a promover
sistemas de inteligencia artificial en salud más equitativos y confiables.
Es un error asumir que la inteligencia artificial es objetiva o imparcial. Los algoritmos
aprenden de datos generados en contextos sociales específicos,variados y repletos de
desigualdades por prácticas clínicas y decisiones humanas. Por tanto, lejos de ser
neutrales, los modelos de IA reflejan las estructuras y sesgos del mundo que los alimenta.
Desde la selección de variables hasta la interpretación de resultados, cada etapa del
desarrollo implica decisiones que pueden favorecer a ciertos grupos y perjudicar a otros.
Reconocer que la IA no es neutral es el primer paso para construir sistemas más justos,
transparentes y clínicamente responsables.
A modo de conclusión, la creciente implementación de modelos de IA en contextos
sanitarios presenta oportunidades significativas para mejorar la eficiencia y precisión
diagnóstica. Sin embargo, sin intervenciones específicas, la IA no solo puede reproducir
desigualdades existentes sino activamente amplificarlas. Es importante mantener los ojos
críticos y no dejar pasar que la inteligencia artificial en medicina no es inherentemente
objetiva. El desafío no es meramente técnico, sino ético y social: debemos diseñar sistemas
de IA que no solo sean precisos, sino también equitativos. Esto requiere equipos
multidisciplinarios, datos representativos y validación rigurosa. La verdadera innovación en
IA médica no solo se medirá por la complejidad algorítmica, sino por su capacidad para
mejorar la atención sanitaria para todos los pacientes, independientemente de su raza,
género o condición socioeconómica. La equidad no debe ser una consideración secundaria,
sino un parámetro fundamental de calidad en el desarrollo e implementación de estas
tecnologías que están transformando la medicina.
La autora usó Claude 3.7 Sonnet, para mejorar la redacción de este texto.
- Amaya-Santos, S., Jiménez-Pernett, J., & Bermúdez-Tamayo, C. (2024). ¿Salud
para quién? Interseccionalidad y sesgos de la inteligencia artificial para el
diagnóstico clínico. Anales del Sistema Sanitario de Navarra, 47(2), e1077. - Leslie, D., Mazumder, A., Peppin, A., Wolters, M. K., & Hagerty, A. (2021). Does «AI»
stand for augmenting inequality in the era of covid-19 healthcare? BMJ, 372. - Wu, H., Sylolypavan, A., Wang, M., & Wild, S. (2022). Quantifying Health Inequalities
Induced by Data and AI Models. Proceedings of the Thirty-First International Joint
Conference on Artificial Intelligence (IJCAI-22), Special Track on AI for Good, 5192- - in the era of covid-19 healthcare? BMJ, 372.
- Cross JL, Choma MA, Onofrey JA (2024)Bias in medical AI: Implications for clinical
decision-making. PLOS Digit Health 3(11):e0000651. - Obermeyer Z, Powers B, Vogeli C, Mullainathan S. Dissecting racial bias in an
algorithm used to manage the health of populations. Science. 2019 Oct
25;366(6464):447-453. doi: 10.1126/science.aax2342. PMID: 31649194. - Tina Hernandez-Boussard, Selen Bozkurt, John P A Ioannidis, Nigam H Shah,
MINIMAR (MINimum Information for Medical AI Reporting): Developing reporting
standards for artificial intelligence in health care, Journal of the American Medical
Informatics Association, Volume 27, Issue 12, December 2020, Pages
2011–2015, https://doi.org/10.1093/jamia/ocaa088
