Luis Eduardo Pino Villarreal MD, M.Sc, MBA. CEO Oxler. Fundador Aipocrates.

La inteligencia artificial (IA) avanza a una velocidad casi inalcanzable, pero además en un mercado dominado por gigantes como OpenAI, Google, Anthropic o Meta en su carrera hacia la IA General, por esto pocos esperábamos que una startup china irrumpiera con un modelo revolucionario del cual todos están hablando.
DeepSeek, compañía fundada en Hangzhou por Liang Wenfeng, ha cambiado el juego con su enfoque de eficiencia, costos reducidos y un compromiso con la apertura y la accesibilidad. Su modelo de gran lenguaje (LLM) DeepSeek-R1 ha superado barreras en rendimiento, despliegue y accesibilidad logrando métricas similares a sus competidores de referencia y generando un impacto masivo en la industria tecnológica y el mercado financiero global. Revisemos brevemente cómo ocurrió esto.
El poder de la destilación en IA
He titulado esta columna como «Distillation is All You Need», parafraseando el icónico artículo de Vasmani que se reconoce con el famoso título: «Attention is All You Need», el cual introdujo los transformers en IA, una nueva estructura de red neuronal que transformó para siempre el subcampo del procesamiento del lenguaje natural y que posteriormente facilitó el desarrollo de la IA generativa, basada en los modelos fundacionales y luego en los LLMs, moviéndose hoy hacia IA agencial (leer columnas relacionadas en http://www.aipocrates.blog).
La destilación de modelos de IA es un proceso en el que se transfieren conocimientos de un modelo grande a otro más pequeño y eficiente sin perder capacidades clave. DeepSeek ha llevado esta estrategia al siguiente nivel, permitiendo la creación de modelos que ofrecen un rendimiento de primer nivel sin requerir los exorbitantes costos computacionales de sus competidores.
DeepSeek-R1 es un claro ejemplo de cómo la destilación y la optimización pueden desafiar el statu quo. Su arquitectura basada en Mixture-of-Experts (MoE) permite activar solo una fracción de sus 671 mil millones de parámetros por consulta, reduciendo el costo computacional sin sacrificar calidad. En benchmarks como el American Invitational Mathematics Examination (AIME), R1 logra un 79.8% de precisión, superando a OpenAI o1 (79.2%). Además, en pruebas como MMLU (Massive Multitask Language Understanding), alcanza un 90.8% de precisión, quedando apenas un punto porcentual por debajo de los modelos más avanzados de OpenAI.
Recientemente sitios especializados como Artificial Analytics han evaluado a DeepSeek incluso frente al último lanzamiento de OpenAI, el modelo o-3 mini-high, miremos los resultados:
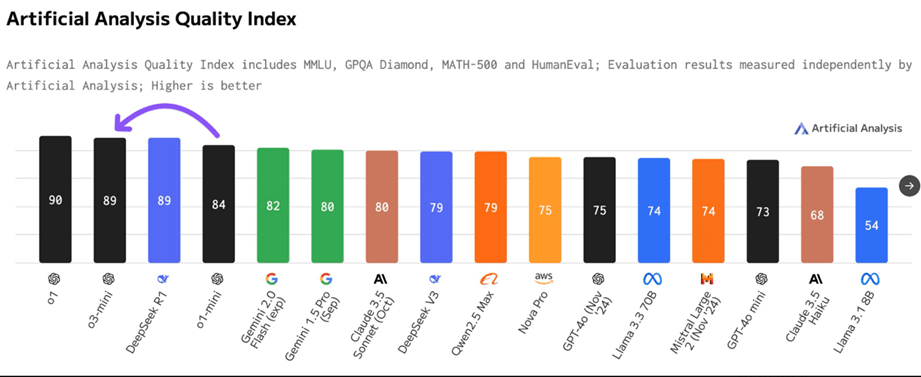
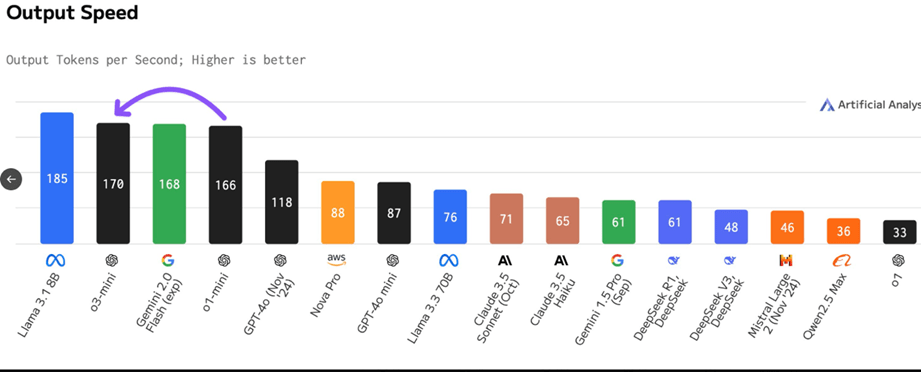
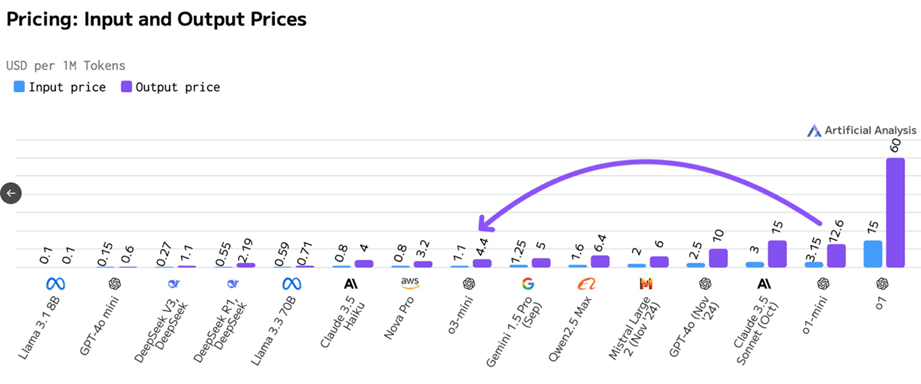
Como podemos ver, si bien en términos de velocidad de las salidas es inferior, el análisis integral lo ubica como un modelo equivalente a los de desempeño superior en los cuales la familia GPT sigue dominando, pero como vemos a un mayor costo.
El enfoque innovador de DeepSeek: Arquitectura y Entrenamiento
DeepSeek-R1 ha adoptado un enfoque novedoso en el desarrollo de modelos de IA, omitiendo el aprendizaje supervisado en su fase inicial. En lugar de utilizar grandes conjuntos de datos etiquetados, el equipo de DeepSeek optó por entrenar su modelo directamente con aprendizaje por refuerzo (Reinforcement Learning – RL). Esta decisión permitió que el modelo desarrollara comportamientos de razonamiento como autoverificación y reflexión sin depender de una estructura de aprendizaje estrictamente supervisada, además se aprovechó de los llamados datos cold start, pero ¿qué es esto?
Uso de datos Cold Start
Para mitigar problemas comunes en modelos entrenados exclusivamente con RL, como salidas repetitivas o mezcla de idiomas, DeepSeek introdujo un conjunto de datos Cold Start. Este conjunto de datos inicial, cuidadosamente curado y previamente decantado desde otros modelos de alto desempeño, le proporcionó al modelo un punto de partida antes de la aplicación completa del aprendizaje por refuerzo, asegurando una base sólida para la generación de conocimiento.
Mixture-of-Experts (MoE) y eficiencia computacional
DeepSeek-R1 emplea una arquitectura Mixture-of-Experts (MoE) que divide la carga computacional activando únicamente una parte específica de sus 671 mil millones de parámetros para cada tarea. Esto significa que, en lugar de utilizar todos los parámetros en cada inferencia, el modelo activa aproximadamente 37 mil millones de parámetros, lo que reduce significativamente los costos de cómputo mientras mantiene una alta capacidad de razonamiento y generación de respuestas precisas.
Destilación y Optimización: La clave del rendimiento de DeepSeek
Uno de los factores más innovadores del enfoque de DeepSeek es su estrategia de destilación. A través de este proceso, se extraen las mejores capacidades de razonamiento del modelo completo y se transfieren a versiones más pequeñas y eficientes. Este proceso no solo mejora la velocidad de inferencia, y también permite que el modelo sea adaptable a entornos con menos capacidad computacional, como dispositivos móviles o sistemas locales. Esta posibilidad de operar fácilmente en sistemas locales (es decir en su propio computador personal) permite que el usuario lo ajuste para usos específicos sin pagar adicionalmente por el uso del modelo a través de conectores (API) como ocurre con los modelos de OpenAI.
DeepSeek ha publicado varias versiones destiladas de su modelo principal, con tamaños que van desde 1.5 mil millones hasta 70 mil millones de parámetros, asegurando que diferentes usuarios y empresas puedan beneficiarse de su tecnología sin necesidad de grandes inversiones en infraestructura. Además, modelos como DeepSeek-V3 han sido optimizados para integrar los patrones de razonamiento de R1, mejorando su rendimiento en tareas complejas como matemáticas, lógica y codificación.
Impacto en la industria y el mercado
El lanzamiento de DeepSeek-R1 generó una sacudida en la industria tecnológica y financiera. Nvidia, cuyo negocio depende de la venta de chips avanzados para entrenar modelos de IA, vio una caída del 18% en su valor de mercado tras el anuncio de DeepSeek. Empresas como OpenAI y Anthropic, que invierten cientos de millones en infraestructura computacional, ahora enfrentan el reto de justificar sus altos costos frente a una alternativa radicalmente más eficiente.
Meta’s Chief AI Scientist, Yann LeCun, lo resumió de forma contundente: «Open-source models are surpassing proprietary ones». Microsoft, por su parte, reconoció la importancia de esta disrupción, con Satya Nadella declarando en el Foro Económico Mundial: «We should take the developments out of China very, very seriously», no voy a traducirlo porque es suficientemente diciente.
Además, la reducción de costos en inteligencia artificial que ofrece DeepSeek podría representar una oportunidad transformadora para países de bajos y medianos ingresos, especialmente en América Latina. La posibilidad de ejecutar modelos de IA eficientes sin depender de infraestructura costosa podría facilitar el acceso a soluciones avanzadas en sectores como la educación, la salud y la optimización de procesos gubernamentales. En economías con presupuestos limitados, este tipo de tecnología tiene el potencial de cerrar brechas tecnológicas y acelerar la digitalización sin requerir inversiones multimillonarias en hardware o licencias de software. Países como Colombia, donde la innovación en IA aún enfrenta barreras económicas, podrían beneficiarse enormemente de modelos accesibles y adaptables como DeepSeek-R1 y los que vendrán a través de estas destilaciones (¡y salud!).
DeepSeek y el futuro de la inteligencia artificial
La historia de DeepSeek refleja un cambio de paradigma en el desarrollo de IA: menos dependencia de infraestructura costosa, más accesibilidad y un enfoque en destilación y eficiencia. En términos prácticos, esto significa:
- Menos monopolización del desarrollo de IA: Pequeñas empresas y startups podrán construir soluciones avanzadas sin depender de las grandes tecnológicas.
- Menor consumo energético: La eficiencia de estos modelos reduce la necesidad de enormes centros de datos, con un impacto positivo en el medio ambiente (el cual está por verse).
- Mayor personalización y adaptación: La posibilidad de ejecutar estos modelos localmente permitirá soluciones de IA más específicas y ajustadas a cada industria. Pequeños desarrolladores y freelancers podrán ajustar y potenciar sus desarrollos a menor costo
- Impacto en el sector salud: DeepSeek tiene el potencial de transformar la medicina mediante la personalización de tratamientos, la optimización de flujos de trabajo clínico y el diagnóstico asistido por IA, especialmente en sistemas de soporte al razonamiento clínico. Modelos como DeepSeek-R1 pueden analizar grandes volúmenes de datos clínicos, identificar patrones complejos y mejorar la toma de decisiones médicas en tiempo real. Esta accesibilidad a IA avanzada podría facilitar la implementación de herramientas diagnósticas de bajo costo en hospitales y clínicas de países con recursos limitados, democratizando la medicina de precisión y mejorando la calidad del cuidado de los pacientes.
La historia de DeepSeek refleja un cambio de paradigma en el desarrollo de IA: menos dependencia de infraestructura costosa, más accesibilidad y un enfoque en destilación y eficiencia. En términos prácticos, esto significa:
- Apertura económica: Pequeñas empresas y startups podrán construir soluciones avanzadas sin depender de las grandes tecnológicas.
- Sostenibilidad: La eficiencia de estos modelos reduce la necesidad de enormes centros de datos, con un impacto positivo en el medio ambiente.
- Personalización: La posibilidad de ejecutar estos modelos localmente permitirá soluciones de IA más específicas y ajustadas a cada industria.
Conclusión
DeepSeek no es una startup más en el ecosistema de IA, sino un símbolo de la transición hacia modelos más accesibles, eficientes y sostenibles. La destilación de modelos, combinada con el enfoque de código abierto, está redefiniendo las reglas del juego. Quizás la lección más importante que nos deja DeepSeek es que la inteligencia artificial no necesita depender de los recursos ilimitados de un puñado de empresas; con estrategias de optimización y destilación, la IA puede democratizarse y alcanzar a todos.
Si algo ha demostrado DeepSeek es que, en el futuro de la inteligencia artificial, distillation is all you need, y que como en la serie del Hombre Nuclear: nos ha llegado el LLM de los (escasos) 6 millones de dólares.
Nota del autor: esta columna se escribió soportada por los modelos DeepSeek R1 y GPT o-1 para ajuste textual y corrección gramatical, se utilizó Grok para generación de imágenes.

Muy interesante. La revolución de la IA abierta para todos.
Me gustaMe gusta
excelente análisis. Observaciones para futuro con menores costo-efectividad. Es nuevo renacer de la IA y de la I humana. Gracias. Veremos a donde vamos en tecnología.
Me gustaMe gusta