Luis Eduardo Pinto, Médico y docente de la Universidad Von Humboldt de Armenia, miembro de AIpocrates.
Introducción
Aunque la IA explicable (XIA) es una solución al desafío de transparentar los modelos de caja negra (MCN) de mayor precisión, afronta sus limitaciones que le impiden garantizar una IA fiable. La explicabilidad procura comprender modelos que fueron creados opacos y de allí derivan algunos problemas actuales de la XAI: incapacidad decomprender plenamente el razonamiento detrás de las decisiones de los MCN, de predecir el efecto de integrar información externa y de controlar el error humano cuando se manejan múltiples factores de entrada. Surge el aparente dilema de escoger entre la precisión de los modelos complejos opacos o la imprecisión de los modelos simples pero transparentes. Sin embargo, la creencia generalizada de que los modelos más complejos ocupan siempre la cima de la precisión es un mito. Machine Learning Interpretable (MCI) es una alternativa menos ambiciosa pero más viable que XIA, mientras se logran transparentar los MCN.
Machine Learning Interpretable (MLI)
Mientras que la explicabilidad busca justificar las decisiones de un modelo, la interpretabilidad se centra en comprender su funcionamiento interno. Esta última permite observar relaciones de causa y efecto en un sistema, identificar problemas y prever el impacto de cambios en las entradas o parámetros.
Como dijimos antes, para diagnosticar cáncer de piel un modelo sería interpretable si podemos entender cómo analiza características de una lesión para emitir un diagnóstico. MLI ofrece un enfoque más paso y paso, desde el diseño.
Un modelo interpretable, por diseño, permite a los usuarios comprender su lógica interna y cómo llega a sus conclusiones. Esta transparencia inherente permite a los usuarios confiar en el modelo y sus predicciones. Generalmente, se acepta que la complejidad de los modelos de Machine Learning (ML) es directamente proporcional a su precisión e inversamente proporcional a su transparencia e interpretabilidad (Figura 1). A su vez, la baja transparencia amenaza su implementación práctica.
La interpretabilidad en los modelos de aprendizaje automático ha cobrado gran relevancia, sobre todo en aplicaciones sensibles como la medicina. El enfoque de MLI busca equilibrar la precisión predictiva con la transparencia en el proceso de toma de decisiones.
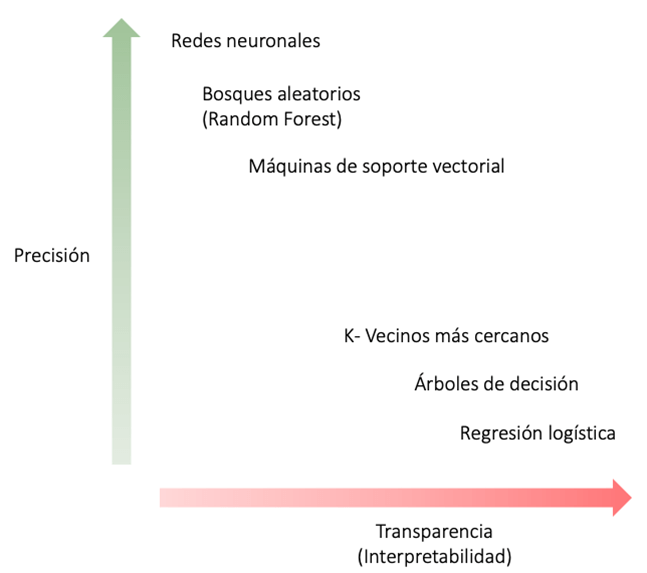
Figura 1. Relación entre precisión y transparencia. Se acepta ampliamente que MCN (parte superior del plano) exhiben mayor precisión sacrificando transparencia mientras que modelos de MCI (parte superior del plano) son más imprecisos pero interpretables. Sin embargo, modelos de MCI bien diseñados pueden llegar a ser precisos, MCN precisos pueden llegar a ser interpretables y MCN no siempre son precisos o eficientes para una determinada tarea.
Aquí hay algunos aspectos que justifican la aproximación de diseño interpretable:
1. Conjunto de Rashomon
Se refiere al conjunto de modelos predictivos razonablemente precisos para un conjunto de datos determinado. Dado que los datos son finitos, puede haber múltiples modelos que logran una precisión similar, incluso si tienen diferentes formas funcionales. Este conjunto de modelos precisos y diversos probablemente incluye al menos un modelo que es interpretable, lo que permite lograr alta precisión sin sacrificar la interpretabilidad.
2. Modelos de MLI con alto rendimiento
Existen ejemplos de modelos interpretables con alto rendimiento en medicina. Por ejemplo, un estudio reciente buscó desarrollar un modelo MLI, llamado BOUND (Bayesian netwOrk for large-scale lUng caNcer Digital prescreening), para facilitar la detección temprana de esta enfermedad en poblaciones chinas. La investigación utilizó datos masivos de más de 5 millones de individuos de casi 5 mil hospitales e instituciones de atención primaria en China. En lugar de un MCN, se utilizó una Red Bayesiana (BN) cuya estructura permitía visualizar las relaciones entre las variables y los factores de riesgo, facilitando la comprensión del modelo por parte de los médicos. BOUND logró un AUC (Área bajo la curva ROC) de 0.866 en la validación interna, 0.848 en la validación externa basada en el tiempo y 0.841 en la validación externa basada en la geografía.
3. Beneficios de los MCN para las empresas
Las empresas pueden obtener beneficios de la propiedad intelectual de un modelo de caja negra, ya que su funcionamiento interno no se revela. Si se utilizara un modelo interpretable, se perderían estos beneficios para estas empresas pero se aceleraría el beneficio social.
4. Creencias sobre MCN e interpretables
Se considera que los MCN pueden detectar patrones sutiles que modelos interpretables como regresiones lineales o árboles de decisión podrían pasar por alto. No obstante, si estos patrones son relevantes y mejoran significativamente las predicciones, un modelo de MCI bien diseñado también podría capturarlos. Esto sugiere que la interpretabilidad no riñe con la capacidad de identificar patrones complejos, sino que ambos aspectos pueden coexistir con un diseño cuidadoso.
Para promover el uso de modelos interpretables en contextos de alto riesgo, se debería priorizar el uso de modelos de MCI siempre que ofrezcan el mismo nivel de precisión que los MCN, reservando estos últimos para casos en los que no existan alternativas igualmente precisas; además, de informar la precisión de los modelos interpretables para permitir a las partes interesadas compararlos.
Existen dos enfoques clave para mejorar la interpretabilidad de los modelos de IA en medicina: las técnicas a priori, que se aplican durante el diseño del modelo, y las a posteriori, que se implementan después del entrenamiento del modelo.
Técnicas a priori:
1. Simplicidad de la arquitectura: Utilizar modelos con estructuras más simples, como modelos lineales, facilita la interpretabilidad, ya que su comportamiento es más fácil de entender y explicar.
2. Ingeniería de características: La selección de características relevantes y la transformación de estas en representaciones significativas pueden hacer que el modelo sea más transparente, al permitir una interpretación más clara de las variables que influyen en las predicciones.
3. Técnicas de regularización: Al limitar la complejidad del modelo y reducir el número de parámetros, la regularización ayuda a que el modelo sea más comprensible y menos susceptible a sobreajuste.
4. Limitación de la profundidad: En redes neuronales, restringir la cantidad de capas evita que el modelo se vuelva demasiado complejo y difícil de interpretar. Los modelos más superficiales suelen ser más fáciles de analizar.
Técnicas a posteriori, algunos ejemplos:
1. LIME (Local Interpretable Model-agnostic Explanations): LIME crea un modelo local más simple y comprensible alrededor de una predicción específica, facilitando la interpretación de modelos complejos.
2. SHAP (SHapley Additive exPlanations): Utiliza la teoría de juegos cooperativos para asignar contribuciones de características a cada variable de entrada, permitiendo una comprensión detallada de cómo cada característica influye en las predicciones del modelo.
3. Visualización de características: Estas técnicas crean visualizaciones retrospectivas basadas en instancias de datos específicas para mostrar las características más relevantes para las decisiones del modelo, proporcionando una comprensión más intuitiva.
4. Análisis de sensibilidad: Evalúa cómo pequeños cambios en las entradas pueden afectar las predicciones del modelo, identificando las características más influyentes y proporcionando una visión más clara de los factores que afectan el comportamiento del modelo.
Construir modelos interpretables requiere un esfuerzo significativo, tanto computacional como de conocimiento del dominio. Hay que definir claramente qué significa la interpretabilidad en el contexto específico y establecer restricciones adecuadas. Esto demanda una comprensión profunda de los factores relevantes en el área de aplicación y un equilibrio entre la complejidad del modelo y su accesibilidad para los usuarios.
“Cajas negras” interpretables
Aunque actualmente carecemos de una explicación completa de MCN, la investigación ya nos está ayudando a entender mejor su funcionamiento.
Las redes neuronales interpretables (INN) son un campo de investigación importante que abarca áreas como el procesamiento de voz, texto, imágenes y la resolución de ecuaciones diferenciales. Estas se clasifican principalmente en:
1. Redes de descomposición de modelo: Convierten métodos analíticos convencionales en capas de redes neuronales, combinando la interpretabilidad de los modelos tradicionales con el aprendizaje de las redes. Según su origen, se dividen en modelos matemáticos, físicos y otros.
2. Redes semánticas: utilizan información visual para mejorar la comprensión del usuario. Este enfoque incluye la visualización de salidas de capas convolucionales, árboles de decisión y gráficos semánticos, asignando significado a la estructura de la red. Estas técnicas, aplicadas tras el diseño de la red, aprovechan la lógica visual humana para explicar modelos opacos.
En otra aproximación reciente, se exploró la interpretabilidad del modelo Claude 3 Sonnet mediante autoencoders dispersos (SAEs), que permitieron extraer millones de características asociadas a conceptos como personas, ubicaciones y seguridad de la IA. Estas características no solo son interpretables, sino que también influyen en las salidas del modelo y se generalizan a múltiples modalidades, como texto e imágenes, indicando su naturaleza abstracta.
La ruta hacia la IA fiable
Dado que la IA explicable (XIA) afronta problemas inherentes a la naturaleza opaca de los modelos complejos, considerados más precisos, un camino viable a la IA fiable resultaría de la combinación óptima de modelos interpretables y precisos a la vez, sean estos complejos (MCN) o no (MCI). Figura 2.

Figura 2. Diagrama de flujo genérico para abordar la opacidad en IA médica y llegar a IA fiable. La IA fiable resultaría de combinar modelos interpretables y precisos a la vez. La IA interpretable puede ser Machine Learning Interpretable (MCI) (modelos creados transparentes) o Modelos de Caja Negra (MCN) precisos e interpretables (modelos creados opacos y luego transparentados).
Conclusión
Es esencial adoptar enfoques como el aprendizaje automático interpretable (MLI) y técnicas tanto a priori como a posteriori para garantizar decisiones informadas, comprensibles y confiables. En el camino hacia una integración más amplia de la IA en contextos sensibles como la medicina, debemos priorizar el desarrollo de modelos que no solo sean precisos, sino también interpretables, fiables y alineados con los valores, preferencias y necesidades de sus usuarios finales. Esto no significa renunciar a los MCN sino seguir investigando cómo transparentarlos.
Declaración: El autor usó ChatGPT para soportar la edición y optimización del texto.
Lecturas recomendadas
- Frasca, M., La Torre, D. et al. Explainable and interpretable artificial intelligence in medicine: a systematic bibliometric review. Discov Artif Intell 4, 15 (2024).
- Linardatos, Pantelis et al. “Explainable AI: A Review of Machine Learning Interpretability Methods.” Entropy (Basel, Switzerland) vol. 23,1 18. 25 Dec. 2020.
- London, Alex John. “Artificial Intelligence and Black-Box Medical Decisions: Accuracy versus Explainability.” The Hastings Center report vol. 49,1 (2019): 15-21.
- Durán, Juan Manuel. “Dissecting scientific explanation in AI (sXAI): A case for medicine and healthcare.” Artif. Intell. 297 (2021): 103498.
- Rudin, Cynthia. “Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.” Nature machine intelligence vol. 1,5 (2019): 206-215.
- Hatherley, Joshua et al. “The Virtues of Interpretable Medical AI.” Cambridge quarterly of healthcare ethics : CQ : the international journal of healthcare ethics committees, 1-10. 10 Jan. 2023.
- Zhang, Shuaijie et al. “Interpretable machine learning model for digital lung cancer prescreening in Chinese populations with missing data.” NPJ digital medicine vol. 7,1 327. 19 Nov. 2024.
- Liu, Zhuoyang, and Feng Xu. “Interpretable neural networks: principles and applications.” Frontiers in artificial intelligence vol. 6 974295. 13 Oct. 2023.
- Anthropic. Scaling Monosemanticity: Insights from Sparse Autoencoders on Claude 3 Sonnet [Internet]. 2024 [citado 2024 Dec 6].
