Autor: Luis Eduardo Pinto. Médico y docente de la Universidad Von Humboldt de Armenia, miembro de AIpocrates.
Introducción
La falta de explicaciones claras en las decisiones automatizadas puede minar la confianza del paciente en la inteligencia artificial (IA) médica. La transparencia en la toma de decisiones es esencial para generar comodidad con las recomendaciones. Los algoritmos de «caja negra», con lógica interna opaca, generan desconfianza en clínicos y pacientes, afectando la comunicación y la relación médico-paciente basada en la comprensión mutua. La explicabilidad y la interpretabilidad surgen como soluciones a estos desafíos (Figura 1). Dedicaremos esta primera entrega a introducir la IA explicable (XAI) y abordaremos IA Interpretable en una entrega posterior. ¡Bienvenidos!

Precisión
La alta precisión garantiza resultados fiables, especialmente en diagnósticos médicos. Modelos avanzados, como redes neuronales profundas (DNN), han demostrado gran precisión en diagnósticos por imágenes, y grandes modelos de lenguaje basados en redes neuronales exhiben habilidades cognitivas que igualan o superan las de los médicos promedio. No obstante, su complejidad puede comprometer la confianza del usuario al dificultar la validación de sus decisiones.
¿Por qué es negra la «caja negra»?
La «caja negra» se refiere a la dificultad para comprender los procesos internos de ciertos sistemas de IA y se debe a la falta de transparencia (opacidad) en su funcionamiento.
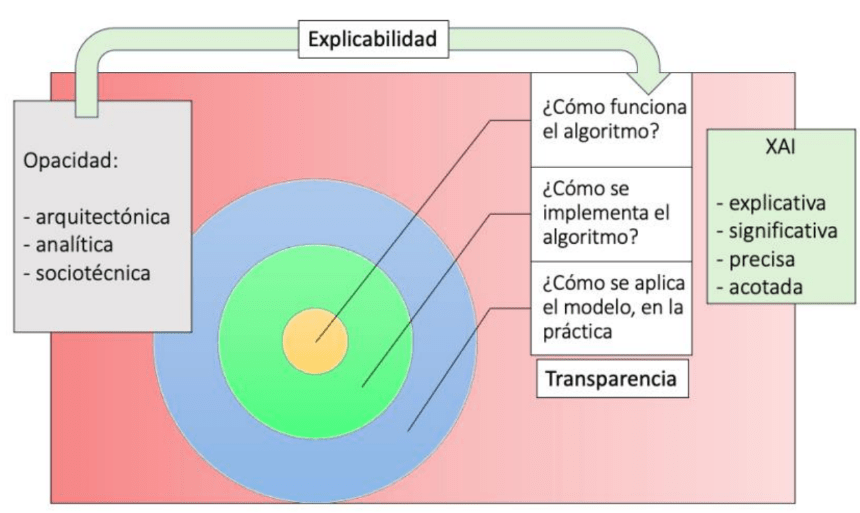
Las causas de la opacidad se pueden dividir en tres categorías:
1. Opacidad arquitectónica:
– Complejidad: Los miles de parámetros de un modelo, usuales en modelos opacos, dificultan la comprensión de sus decisiones.
– Representacional: Los sistemas de IA utilizan representaciones que no coinciden con los conceptos humanos.
– Opacidad de enlace: Aunque se entienda el funcionamiento técnico, es difícil interpretar los resultados en su relación con el mundo real.
2. Opacidad analítica:
– Recursos limitados: La falta de recursos como tiempo o potencia computacional limitan la transparencia al impedir la validación de los resultados del modelo.
– Conocimiento perdido: En sistemas heredados, la opacidad puede surgir por la pérdida de conocimiento sobre su diseño original.
– Dependencia epistémica: La comprensión del sistema depende del conocimiento experto.
3. Opacidad sociotécnica:
– Ocultamiento intencional: En ocasiones, la opacidad es deliberada, ya sea por razones comerciales, éticas o de seguridad.
– Falta de habilidades: Un sistema puede ser transparente para expertos pero opaco para usuarios sin formación técnica.
Las consecuencias de la opacidad incluyen dificultades en la rendición de cuentas, pérdida de confianza y obstáculos para mejorar los sistemas. En contextos de alto riesgo, como la atención médica y la justicia, estas consecuencias son especialmente problemáticas. Por tanto, se propone transparentar modelos de IA.
Existen diversos tipos de transparencia, entre ellos:
1. Funcional: Comprensión del funcionamiento algorítmico del sistema.
2. Estructural: Entender cómo se implementa el algoritmo en el código.
3. Ejecutiva: Comprender cómo se ejecuta el programa en un caso específico, incluyendo datos y hardware utilizados.
¿Debe la IA ser transparente?
La transparencia en la IA médica es un tema complejo. Los médicos justifican sus decisiones en conocimiento causal, aunque este sea incompleto, y la incertidumbre es parte de la medicina. Muchas decisiones se basan en experiencia e intuición, incluso sin entender plenamente los mecanismos subyacentes. Además, no todos los médicos están formados para evaluar evidencia, comunicar estadísticas o justificar decisiones en detalle.
Aunque menos precisos que las máquinas, los médicos generan confianza por la familiaridad con su proceso, mientras que a la IA, más precisa, se le exige mayor transparencia, reflejando el intento de la IA de imitar la inteligencia humana, aunque sean diferentes.
La crítica a la opacidad de la IA no siempre es justa. En medicina, la efectividad práctica a menudo precede a la comprensión teórica, como ocurrió con la aspirina o las penicilinas, útiles antes de la comprensión teórica de sus mecanismos.
Exigir transparencia absoluta podría retrasar los beneficios de la IA. Si un sistema demuestra precisión empírica, tiene casos de uso claros y controles para evitar sesgos, comprender su funcionamiento interno no debería ser imprescindible para implementarlo.
IA explicable
Aunque los médicos pueden no ser siempre conscientes de los detalles de sus decisiones, deben poder explicarlas y hacerse responsables por omitir explicaciones.
La explicabilidad es la capacidad de un modelo para proporcionar justificaciones claras y comprensibles para decisiones específicas (Figura 2). Va más allá de entender su funcionamiento general (interpretabilidad), ya que incluye la habilidad de explicar cómo factores concretos influyen en cada resultado.
Por ejemplo, un modelo de IA para diagnosticar cáncer de piel es interpretable si podemos entender cómo analiza características como tamaño, forma y color de una lesión para emitir un diagnóstico. El modelo sería explicable si, además de ser interpretable, detalla las características de una lesión cutánea que lo llevan a clasificarla como cáncer. En este sentido, la explicabilidad abarca y amplía la interpretabilidad. Además, suele enfocarse en modelos ya desarrollados y busca reducir la opacidad de los modelos.
La transparencia en la IA es crucial no sólo para su comprensión, sino para asegurar su cumplimiento ético. Si no entendemos cómo funciona un sistema de IA, es difícil evaluar si cumple con principios éticos fundamentales.
Debe compartirse información que respalde las decisiones de los modelos de IA, especialmente en contextos críticos, como los ámbitos legal y médico. También es necesario identificar errores, sesgos o vulnerabilidades en el modelo para prevenir consecuencias negativas y garantizar su fiabilidad. Además, la comprensión del funcionamiento del modelo permite su mejora continua.
El Instituto Nacional de Estándares y Tecnología propone cuatro principios clave para la XAI:
1. Explicación: El sistema debe ser capaz de describir cómo llegó a una conclusión, qué factores influyeron en su decisión.
2. Significado: Las explicaciones no solo deben existir, sino ser comprensibles y relevantes según el nivel de conocimiento del usuario.
3. Precisión: La explicación debe ser fiel al funcionamiento del modelo, diferenciando entre precisión de la explicación y precisión de la decisión.
4. Límites: El sistema debe reconocer sus limitaciones y las situaciones en las que no puede operar con fiabilidad.
Es esencial reconocer que la XAI se distingue de las explicaciones científicas, ya que las explicaciones basadas en IA, como las predicciones, no son necesariamente científicas. Para ser científica, la lógica interna debe vincular el explanandum (resultado) con el explanans (explicación), basándose en principios científicos; debe adaptarse a las necesidades de diferentes interesados (ej: médicos y pacientes) sin perder la objetividad, y la calidad de la explicación debe medirse por su poder explicativo, el control humano sobre el proceso y su integración con la práctica científica y clínica.
Actualmente, hay una tendencia de intentar «explicar» modelos complejos, pero las explicaciones generadas son a menudo inexactas y no reflejan con fidelidad el modelo original.
Problemas con la XAI
La explicabilidad procura comprender modelos que fueron creados opacos. De allí derivan algunos problemas actuales de la XAI.
Existe una creencia generalizada de que los modelos más complejos son necesariamente más precisos. Sin embargo, esto es un mito. En muchos casos, especialmente cuando se trabaja con datos estructurados y bien definidos, modelos interpretables, como la regresión logística, pueden lograr un rendimiento comparable al de MCN más complejos, como las DNN o los árboles de decisión potenciados.
Las explicaciones generadas por modelos «explicables» no replican con exactitud el comportamiento de los MCN, suelen carecer del detalle necesario para comprender plenamente el razonamiento detrás de las decisiones, los efectos de integrar información externa en el riesgo estimado son impredecibles y el riesgo de errores humanos puede incrementarse cuando se manejan múltiples factores de entrada.
Frente a estas limitaciones, el desarrollo de IA interpretable se presenta como una alternativa menos ambiciosa pero más viable, centrándose en el diseño de modelos transparentes.
Conclusión
La implementación de la IA en medicina exige un delicado equilibrio entre precisión y explicabilidad. Si bien la opacidad de los MCN plantea retos éticos y prácticos, los sistemas altamente precisos han demostrado un valor significativo, lo que refuerza la necesidad de continuar explorando formas de explicarlos. Entretanto, es necesario diseñar modelos que no solo sean precisos, sino también interpretables, fiables y alineados con los valores, preferencias y necesidades de sus usuarios finales. En nuestra próxima entrega abordaremos la opción del Machine Learning Interpretable. ¡Los esperamos!
Declaración: El autor usó ChatGPT para soportar la edición y optimización del texto, y para generar la imagen de la figura 1.
Lecturas recomendadas
- Freiman, O. Making sense of the conceptual nonsense ‘trustworthy AI’. AI Ethics 3, 1351–1360 (2023).
- Saranya A, Subhashini R. A systematic review of Explainable Artificial Intelligence models and applications: Recent developments and future trends. Decis Anal J. 2023;7:100230.
- Facchini, A., Termine, A. (2022). Towards a Taxonomy for the Opacity of AI Systems. In: Müller, V.C. (eds) Philosophy and Theory of Artificial Intelligence 2021. PTAI 2021. Studies in Applied Philosophy, Epistemology and Rational Ethics, vol 63. Springer, Cham.
- Mann, Sara et al. “Sources of Opacity in Computer Systems: Towards a Comprehensive Taxonomy.” 2023 IEEE 31st International Requirements Engineering Conference Workshops (REW) (2023): 337-342.
- Frasca, M., La Torre, D. et al. Explainable and interpretable artificial intelligence in medicine: a systematic bibliometric review. Discov Artif Intell 4, 15 (2024).
- Linardatos, Pantelis et al. “Explainable AI: A Review of Machine Learning Interpretability Methods.” Entropy (Basel, Switzerland) vol. 23,1 18. 25 Dec. 2020.
- London, Alex John. “Artificial Intelligence and Black-Box Medical Decisions: Accuracy versus Explainability.” The Hastings Center report vol. 49,1 (2019): 15-21.
- Phillips PJ, Hahn CA, Fontana PC, Yates A, Greene K, Broniatowski DA, Przybocki MA. Four Principles of Explainable Artificial Intelligence. NISTIR 8312 [Internet]. 2021 [citado 2024 Dec 6].
- Russo, F., Schliesser, E. & Wagemans, J. Connecting ethics and epistemology of AI. AI & Soc 39, 1585–1603 (2024).
- Durán, Juan Manuel. “Dissecting scientific explanation in AI (sXAI): A case for medicine and healthcare.” Artif. Intell. 297 (2021): 103498.

Este artículo de gran calidad me ha impulsado a una profunda reflexión, más allá de la comprensión de la IA médica, sobre los procesos y modelos de decisión que utilizo en mi práctica clínica.
Me gustaMe gusta