«El mundo que hemos creado es un proceso de nuestro pensamiento. No puede cambiarse sin cambiar nuestra forma de pensar.» Albert Einstein
Dra. Alexandra Jiménez. MD Pediatra Intensivista. MCs Inteligencia Artificial. Miembro fundador Aipocrates
La reciente tragedia en Valencia tras la DANA (Depresión Aislada en Niveles Altos) nos lleva pensar en la paradoja del uso de la Inteligencia artificial (IA). Porque si bien es cierto, es una herramienta que puede mejorar las predicciones y las respuestas ante desastres, su aumento exponencial genera una significativa huella ambiental que contribuye a la crisis climática. Hay modelos robustos de IA para hacer frente al cambio climático, pero su adopción en mundo real es baja y su impacto por lo menos en situaciones tan criticas y mediáticas no es significativa.
En salud ocurre un fenómeno similar, porque si bien hay un auge de la IA que promete mejorar acceso, diagnóstico y pronostico, el uso intensivo de datos para entrenamiento de modelos tiene gran consumo de energía y debido a la baja generalización de estas soluciones resulta poco costo eficiente desde el punto de vista de sostenibilidad ambiental.
¿Cómo afrontar la paradoja de la IA que puede ser verdugo y a la vez redentor en áreas tan complejas, y tan relevantes para el ser humano, como lo son el medio ambiente y la salud? Pues bien, después de revisar los desafíos en las dos áreas y de encontrar los puntos críticos en común, se plantea la adopción de un modelo estructurado para inclinar la balanza de la IA hacia un resultado más prometedor.
INTELIGENCIA ARTIFICIAL Y CAMBIO CLIMÁTICO
El Programa Mundial de Investigaciones Climáticas reúne proyecciones climáticas de varios modelos para tratar de entender los cambios climáticos pasados, presentes y futuros, realizan simulaciones de clima físico y ciclos biogeoquímicos, pero enfrentan aun varios desafíos, en primer lugar tienen baja capacidad de generalizar, un costo computacional alto que no permite que sean escalables , además de una escasez de datos observacionales de alta calidad y una importante falta de interpretabilidad y mecanismos de causalidad, lo que limita la comprensión de los resultados y que podría conducir a interpretaciones erróneas sobre el cambio climático, además de estar sujetos en los últimos años a una variabilidad extrema que no permite detección de patrones precisos.
Para predecir inundaciones, por ejemplo, se necesita un volumen muy importante de datos de entrenamiento para que se puedan evitar errores de predicción, debido a factores como la calidad de los datos y la complejidad de las tareas. Por ejemplo, un método simple como el modelo de clasificación binaria para las inundaciones puede no representar con precisión todos los tipos de inundaciones y se requiere un modelo más complejo que incluya las condiciones climáticas fluctuantes, el nivel de precipitaciones y la regularidad de la forma de la masa terrestre.
Así mismos conjuntos de datos históricos en aprendizaje automático (ML) tienen desafíos relacionados con el equilibrio entre varianza y sesgo. El objetivo es que estos modelos generalicen bien a nuevos datos, pero ajustar demasiado los modelos a datos pasados puede llevar a errores en predicciones futuras, especialmente en el contexto del cambio climático. Sin embargo los modelos muy simplificados con alto sesgo pueden tener rendimiento inadecuado con precisión y utilidad limitada. Factores como las imágenes inexactas y los ángulos de visión incorrectos también pueden dificultar la detección de desastres, este problema requiere técnicas de aprendizaje profundo y multisensor, así como la integración de fuentes heterogéneas, como las redes sociales y los dispositivos IoT, que generan más información en tiempo real.
.

Figura 1 Adapatada de Eyring, V., Pushing the frontiers in climate modelling and analysis with machine learning. Nat. Clim. Chang. 14, (2024). Ejes de trabajo modelos en análisis climático
Los sistemas de IA, en particular los modelos de aprendizaje profundo, están enfocados no solo la generación de alertas tempranas, sino también las evaluaciones de vulnerabilidad, a través de procesamiento de datos por satélite, sin embargo requieren importantes recursos computacionales y elevado consumo de energía, por lo que se están implementado modelos climáticos híbridos quecombinen machine learning y leyes físicas para captar patrones y escalar su uso, se han encargado también de integrar las dinámicas atmosféricas, terrestres y oceánicas, que pueden afectar la replicabilidad y generar incertidumbre, todo con un enfoque colaborativo intersectorial, y por último y no menos desafiante, posibilidad de crear gemelos digitales para poder reproducir variaciones climáticas realmente significativas. (ver figura 1)
Sin embargo, estos esfuerzos, han representado también un volumen de datos tan grande que 2019, un estudio de Strubell et al. estimó que el entrenamiento de un solo modelo de IA grande puede emitir tanto dióxido de carbono como cinco automóviles a lo largo de su vida útil. Esto sin contar que si se hace una evaluación del ciclo de vida útil de las tecnologías estas generan huella ambiental desde la fabricación, por la extracción de materias primas en algunas de ellas metales “raros” donde el procesamiento de una sola tonelada puede producir hasta dos mil toneladas de residuos tóxicos, si se evalúa la operación hay un consumo elevado de electricidad de hecho se estima que para el 2025 la industria de las TIC podría consumir el 20% de la electricidad mundial, ahora bien en la eliminación, seguimos con un inapropiado uso de los desechos electrónicos que creció de 35 millones de toneladas en 2010 a 50 millones 2018. Esta realidad obliga a que se generen modelos de IA más compactos y computacionalmente eficientes, así como las prácticas de computación verde, (voltaje dinámico y el escalado de frecuencia) que pueden reducir efectivamente el consumo de energía y disminuir esa huella.
HUELLA AMBIETAL DE LA IA EN SALUD
Resulta paradójico que usar la IA para gestionar la toma de decisiones en salud, genera también en una huella ambiental porque se usan grandes conjuntos de datos, algoritmos complejos y que requieren actualizaciones frecuentes, siendo responsables del 4,4% de las emisiones mundiales de gases de efecto invernadero. De hecho, en el 2020, un informe de la Agencia Internacional de la Energía informó que los centros de datos representan el 1% del consumo mundial de electricidad.
La responsabilidad de la huella ambiental debe estar presente desde la concepción de los modelos, pensar más allá y definir si tiene un impacto sobre los objetivos de desarrollo sostenible y si su uso además de beneficiar a los usuarios primarios, favorece el cuidado del planeta, un ejemplo, son las aplicación de técnicas de IA en radiología para la reducción del ruido de la imagen y la obtención de imágenes de alta velocidad, que logran disminuir el tiempo de obtención de imágenes y con esto el consumo energía requerido; otro ejemplo de uso eficiente de recursos está en los sistemas de apoyo a la toma de decisiones, porque diagnósticos más precisos reducen la necesidad de repetir los exámenes y minimizan el desperdicio de recursos. De hecho hoy la investigación de IA en salud ha pasado de solo buscar “precisión” a evaluar cuál es el porcentaje de adopción clínica y determinar si hay impacto centrado en el paciente, como mayor supervivencia, una mejor calidad de vida y si trae consigo una práctica de sostenibilidad ambiental.
Teniendo en cuenta que la costo-eficiencia en los modelos de salud involucra a todo un ecosistema es llamativo encontrar que el 85% de los proyectos de ciencia de datos/ML/AI no logran los objetivos declarados, es más, las organizaciones de salud continúan en su arduo trabajo de su transformación digital , pero solo el 29% logra resultados comerciales relevantes , además solo el 39% de las empresas gestionan los datos como un activo y quienes lo hacen tienen resultado contrario a la expectativa general del impacto de las tecnologías de IA , que proyectaba beneficios para las instituciones y una adopción masiva por parte de los profesionales. La adopción de algoritmos de soporte a la decisión clínica no ha sido masiva, a pesar del aumento en el número de publicaciones sobre inteligencia artificial en medicina que pasaron de 1614 en el año 2000 a 58.458 para el año 2022, lo que representa un aumento de 36 veces; de hecho pasamos del auge del diagnóstico y las técnicas de razonamiento a las consideraciones éticas, herramientas de apoyo a la decisión médica y aplicaciones en mundo real.
¿Qué ha pasado entonces? la razón clave de estos fracasos, para muchos autores está relacionada con la falta de una metodología adecuada, el establecimiento de plazos realistas, la coordinación de tareas, y el diseño de un marco de gestión de proyectos adecuado. Los proyectos tienen centro los datos, pero algo más importante hoy, es que las personas que manejan los datos sean proactivos y curiosos, que puedan contar una historia con los datos y visualizar los conocimientos de forma adecuada, en suma, que tengan una visión empresarial.
CRISP-DM
Los modelos híbridos en salud y cambio climático enfrentan desafíos similares: Altos costos computacionales y limitación en la generalización, problemas de replicabilidad y generalización, manejo de la incertidumbre en eventos extremos, limitaciones en la calidad y disponibilidad de datos, la necesidad de interpretabilidad y causalidad, por lo que se hace necesario establecer una metodología que aborde la forma como pueden enfocar estos problemas .
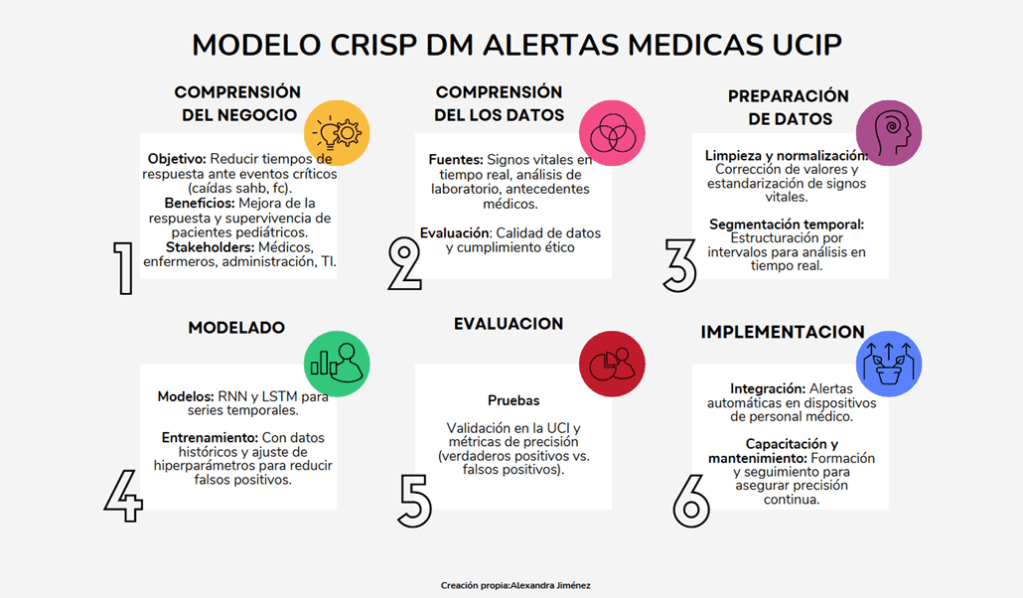
Esta es Cross-Industry Standard Process for Data Mining, más conocida como CRIPS_DM, que se introdujo por primera vez en 1999, es una metodología usada en proyectos y minería de datos, que se compone de 6 fases, que en esta columna se han ajustado específicamente a soluciones de índole tecnológico en salud
- Comprensión del Negocio
Implica definir el objetivo del proyecto, con el beneficio real que tiene y a quienes estará impactando no solamente en beneficios económicos, sino también a quienes con su uso le encuentran valor, como por ejemplo, los pacientes, en términos de calidad de vida, resultados en salud, experiencia y costos de tratamiento; y para profesionales de salud en términos eficiencia en toma de decisiones y optimización de flujos de trabajo.
- Comprensión de los datos
En esta fase se evalúa la accesibilidad y calidad de los datos, las estructuras de estos (imágenes, datos de laboratorios, tendencias de signos vitales, historia clínica ) y se consideran las pautas éticas y de privacidad para manejar la información de los pacientes
- Preparación de los Datos
implica un arduo trabajo de limpieza, donde los datos faltantes, la revisión de los datos críticos y los valores extremos, deben ser revisado por un clínico.
- Modelado
La selección de algoritmos de IA adecuados y la decisión entre enfoques.: ¿Qué necesita que el modelo prediga o analice?, ¿Cuál es el objetivo, identificar enfermedades, prever complicaciones, o analizar patrones en datos de salud?, en la siguiente table se resumen algunos ejemplos.
| Objetivo | Tipo de Problema | Modelo Sugerido | Tipo de Aprendizaje | Descripción | Caso de Uso |
| Clasificación de Riesgo de Complicaciones | Clasificación | Árbol de decisión, Bosque aleatorio, Regresión logística | Aprendizaje Supervisado | Estima el riesgo de complicaciones en pacientes, permitiendo categorizar en bajo, medio o alto riesgo. | Clasificar pacientes pediátricos en riesgo de complicaciones respiratorias en UCI. |
| Predicción de Costos de Tratamiento | Regresión | Regresión lineal, Gradient Boosting | Aprendizaje Supervisado | Predice costos futuros de tratamiento basándose en factores clínicos y antecedentes médicos. | Calcular el costo previsto de un tratamiento a largo plazo para pacientes adultos con enfermedades crónicas. |
| Pronóstico de Descompensación en Urgencias | Series Temporales | LSTM, ARIMA, Redes Neuronales Recurrentes (RNN) | Aprendizaje de Series Temporales | Predice eventos críticos inminentes en urgencias basándose en datos en tiempo real, permitiendo intervención rápida. | Anticipar descompensaciones en adultos con insuficiencia cardíaca en urgencias. |
| Segmentación de Pacientes para Cuidados Personalizados | Agrupamiento | K-Means, DBSCAN, Modelos de Mezcla Gaussiana | Aprendizaje No Supervisado | Agrupa pacientes con características similares para adaptar el cuidado según sus necesidades específicas. | Agrupar a adultos con patrones de síntomas similares en una clínica de manejo del dolor crónico. |
| Predicción de Adherencia al Tratamiento | Clasificación Probabilística | Redes bayesianas, Regresión logística | Aprendizaje Supervisado | Estima la probabilidad de que un paciente cumpla con su tratamiento, ayudando a identificar riesgos de abandono. | Predecir si un niño con asma seguirá su tratamiento domiciliario de manera constante. |
5.Evaluación
Uso de Indicadores Clave de Desempeño (KPI) buscan determinar si el trabajo con Big Data en salud transformó la calidad, cantidad y precisión de la información, o si solo mejoraron el proceso de toma de decisiones en salud; así como si su implementación tiene alguna utilidad percibida por pacientes o profesionales y por último si tiene impacto a largo plazo en costos y/o eficiencia
6.Implementación
La fase final implica planificar, implementar, monitorear y mantener el modelo en los sistemas de salud. Asegurar la inversión, para soporte de la tecnología y hardware adicional, adaptación de la cultura organizacional, para dar respuesta en tiempo real a la información recibida y los procedimientos para gestionar incidentes de seguridad, así como en uso de una interfaz de usuario adecuada
A continuación, se realiza un ejemplo de caso de uso de metodología CRIPS DM para una problemática en cuidado intensivo pediátrico, las alertas medicas por variaciones significativas en signos vitales particularmente donde se llevan registros manuales cada 30 o 60 minutos, teniendo en cuenta que los descensos frecuentes en la presión arterial o en la saturación de oxihemoglobina pueden ser decisivas en términos de supervivencia y discapacidad, es un desafío poder tener un sistema de alertas en tiempo real.
Para llevar a casa
Recuerdo que cada año Bogotá durante el pico respiratorio, enfrentábamos un desafío de sobreocupación, escasez de recursos y paradójicamente mayores ingresos en los servicios de pediatría, de hecho, usábamos modelos basados en datos históricos para gestionar las necesidades en términos de personal e insumos, pero hoy, en una ciudad que se debate entre lluvias torrenciales y racionamiento por sequias, es imposible seguir haciendo lo mismo. El medio ambiente, nos obliga a identificar nuevas formas de gestión de datos, generar otros modelos de predicción, y a usar, no solo la inteligencia artificial, sino la inteligencia humana para liderar, innovar y trabajar en equipo y así afrontar esta nueva realidad. Hay comprender que hacemos parte de un ecosistema y que, si queremos generar una verdadera transformación, no hay que temer a visiones como las planteadas por la metodología CRIPS DM, que nos invita a ampliar el campo de acción, integrar otras disciplinas, hacernos más preguntas y a no olvidar que cuando usamos IA en salud tenemos un triple compromiso, con los pacientes, con los profesionales de la salud y por supuesto con el medio ambiente.
Referencias
Ueda D, Walston. Climate change and artificial intelligence in healthcare: Review and recommendations towards a sustainable future. Diagn Interv Imaging. 2024 Jun 24:S2211-5684(24)00138-4. doi: 10.1016/j.diii.2024.06.002. Epub ahead of print. PMID: 38918123.
Eyring, V., Collins, W.D., Gentine, P. et al. Pushing the frontiers in climate modelling and analysis with machine learning. Nat. Clim. Chang. 14, 916–928 (2024). https://doi.org/10.1038/s41558-024-02095
NewVantage Partners LLC. (2021). NewVantage Partners Releases 2021 Big Data and AI Executive Survey: The Journey to Becoming Data-Driven.
Saltz JS, Krasteva I. Enfoques actuales para la ejecución de proyectos de ciencia de big data: una revisión sistemática de la literatura. PeerJ Comput Sci. 21 de febrero de 2022; 8:E862. doi: 10.7717/peerj-cs.862. PMID: 35494858; PMCID: PMC9044260.
Roland Roller,. 2024. “Data Processing in Healthcare Using CRISP” in Technology in Healthcare: Introduction, Clinical Impacts, Workflow Improvement, Structuring and Assessment. Edited by Brian Pick ering, Roland Roller, Holmer Hemsen, Gerrit J. Noordergraaf, Igor Paulussen and Alyssa Venema. pp. 316–324. NowPublishers. DOI: 10.1561/9781638282372.ch25
Kolyshkina I, Simoff S. Interpretability of Machine Learning Solutions in Public Healthcare: The CRISP-ML Approach. Front Big Data. 2021 May 26;4:660206. doi: 10.3389/fdata.2021.660206. PMID: 34124652; PMCID: PMC8187858.
Shi J, Bendig D, Vollmar HC, Rasche P. Mapping the Bibliometrics Landscape of AI in Medicine: Methodological Study. J Med Internet Res. 2023 Dec 8;25:e45815. doi: 10.2196/45815. PMID: 38064255; PMCID: PMC10746970.
Energy and policy considerations for deep learning in NLParXiv [csCL] (2019), 10.48550/arXiv.1906.02243
Health care’s climate footprint: the health sector contribution and opportunities for actionEur J Public Health, 30 (2020), pp. ckaa165-ckaa843
The global E-waste monitor 2020: quantities, flows and the circular economy potential. United Nations University (UNU), International Telecommunication Union (ITU) & International Solid Waste Association (ISWA)Bonn/Geneva/Rotterdam (2020), p. 120
Available athttps://www.itu.int/en/ITU-D/Environment/Documents/Toolbox/GEM_2020_def.pdf
Katirai, A. Los costes medioambientales de la inteligencia artificial para la sanidad. ABR 16, 527–538 (2024).https://doi.org/10.1007/s41649-024-00295-4
