Por Luis Eduardo Pinto,
Médico y docente de la Universidad Von Humboldt de Armenia, miembro de AIpocrates.
Introducción
La capacidad de leer y evaluar críticamente reportes sobre Inteligencia Artificial y Machine Learning (IA/ML) en salud es una destreza esencial para los profesionales de la salud. Aunque en AIpocrates ya hemos abordado, tanto de forma general como a profundidad, conceptos y procesos de ML en publicaciones anteriores, esta entrega tiene un enfoque distinto y complementario: proporcionar una estrategia sistemática y práctica para guiar la lectura de un artículo de investigación en salud que use IA/ML.
El presente enfoque se basa en el concepto de transposición didáctica, que permite adaptar un contenido complejo en algo accesible y comprensible, sin perder rigor. En este sentido, también aplicamos una cuidadosa vigilancia epistemológica para asegurar que los conceptos se presenten de manera correcta, evitando malentendidos o simplificaciones erróneas.
Este tutorial está pensado para facilitar el proceso de leer un artículo, y valorar su calidad y relevancia. Piense en un artículo que intenta responder cómo se desempeña un algoritmo de aprendizaje supervisado, en comparación con un estándar de referencia, para predecir una clase clínica como podría ser la presencia de cáncer de ovario a partir de imágenes histopatológicas o la presencia de depresión a partir de datos textuales de historias clínicas.
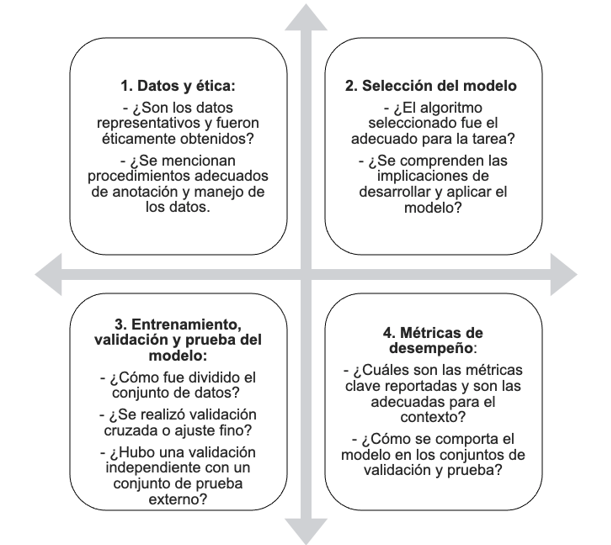
1. Datos: origen, anotación, representatividad y ética
El primer aspecto crucial es la calidad de los datos utilizados para entrenar y evaluar el modelo. Es necesario identificar de dónde provienen los datos, cómo fueron anotados (es decir, etiquetados con los resultados que el modelo debe predecir), y si son representativos de la población a la que se pretende aplicar el modelo. Un modelo entrenado en una población no representativa podría fallar cuando se aplique a otras.
Además, los artículos deben abordar los aspectos éticos en el manejo de los datos, como el consentimiento informado y la protección de la privacidad. Los datos en salud suelen ser sensibles, por lo que es esencial que los autores especifiquen cómo se garantizaron estos principios.

2. Selección del modelo: ¿Era el algoritmo adecuado para la tarea?
En IA/ML, la selección del algoritmo correcto es crucial para el éxito de la tarea que se desea abordar. Es recomendable que el lector esté familiarizado con los diferentes algoritmos disponibles, lo que facilitará la evaluación de la idoneidad de la selección realizada. El artículo debe especificar claramente la tarea a realizar (por ejemplo, clasificación) y el algoritmo elegido para dicha tarea (por ejemplo, máquina de soporte vectorial).
La elección del modelo adecuado depende de varios factores: la complejidad de la tarea de predicción, la necesidad de intervención humana en el proceso, la cantidad de datos de entrenamiento disponibles y la interpretabilidad del modelo. Generalmente, tareas y conjuntos de datos simples pueden abordarse con modelos menos complejos, mientras que aquellas más complejas requieren algoritmos más sofisticados.
Es importante considerar que los modelos simples son generalmente más fáciles de implementar y entender, lo que favorece su interpretación. Por otro lado, los modelos complejos, aunque pueden ofrecer un rendimiento superior en ciertas circunstancias, presentan mayores desafíos tanto en su implementación como en su interpretación. Por ejemplo, una red neuronal puede resultar excesivamente costosa y poco transparente para una tarea simple, mientras que un algoritmo más sencillo puede ser insuficiente para resolver una tarea compleja de manera efectiva.
Finalmente, es esencial cuestionarse si el modelo utilizado aborda una tarea relevante y necesaria en la práctica clínica.

3. Proceso de entrenamiento, validación, ajuste fino y prueba: ¿Cómo se desarrolló el modelo?
Después de analizar los datos, es fundamental comprender los procesos de desarrollo del modelo. Esto incluye varias etapas clave (Figura 1), que describimos enseguida:
3.1 Entrenamiento: En esta fase, el modelo aprende a partir de un conjunto de datos etiquetados. Aquí es importante que el artículo mencione qué tipo de algoritmo de ML fue utilizado (redes neuronales, árboles de decisión, etc.) y si hubo un ajuste de hiperparámetros.
Ajuste fino de hiperparámetros (AFH): Los hiperparámetros son parámetros que no se aprenden directamente durante el entrenamiento, sino que deben ser establecidos antes de este. Ejemplos incluyen la tasa de aprendizaje, el número de capas en una red neuronal y la cantidad de muestras de datos que se utilizan en una única iteración del entrenamiento antes de que se actualicen los pesos del modelo. El AFH implica probar diferentes combinaciones de estos valores para encontrar la configuración que maximiza el rendimiento del modelo.
3.2 Validación: La validación se refiere al proceso de medir el rendimiento del modelo durante su desarrollo, normalmente utilizando técnicas como la validación cruzada, donde el conjunto de datos se divide en partes y el modelo se entrena varias veces, usando diferentes combinaciones de entrenamiento y validación. En esta etapa puede ocurrir subajuste o sobreajuste.
El subajusteocurre cuando el modelo es demasiado simple o no ha aprendido lo suficiente de los datos, lo que resulta en un bajo rendimiento tanto en los datos de entrenamiento como en los de validación. Se corrige aumentando la complejidad del modelo, utilizando modelos más avanzados o redes neuronales más profundas; ajustando hiperparámetros; incluyendo más características relevantes, o permitiendo un mayor ajuste del modelo.
El sobreajusteocurre cuando el modelo ha aprendido demasiado bien los detalles y el ruido de los datos de entrenamiento, lo que le permite funcionar bien en esos datos pero mal en datos nuevos (como los de validación o prueba). Se corrige reduciendo la complejidad del modelo y utilizando técnicas como la regularización, la validación cruzada y el early stopping, que ayudan a limitar el ajuste excesivo.
Ajuste de modelos preentrenados: En este contexto implica adaptar un modelo preentrenado a un conjunto nuevo de datos más específico, con el objetivo de mejorar la precisión del modelo en tareas específicas, aprovechando el aprendizaje previo sin necesidad de entrenar un modelo desde cero. De esta manera el modelo se entrena con una tasa de aprendizaje más baja, permitiendo así que el modelo ajuste sus pesos para mejorar el rendimiento en la nueva tarea sin perder el conocimiento adquirido previamente.
3.3 Prueba independiente: Es fundamental que el modelo haya sido probado con un conjunto de datos independiente. Esto garantiza que el rendimiento reportado no se debe a sobreajuste con los datos de entrenamiento o validación. La ausencia de esta prueba puede comprometer la validez del modelo.
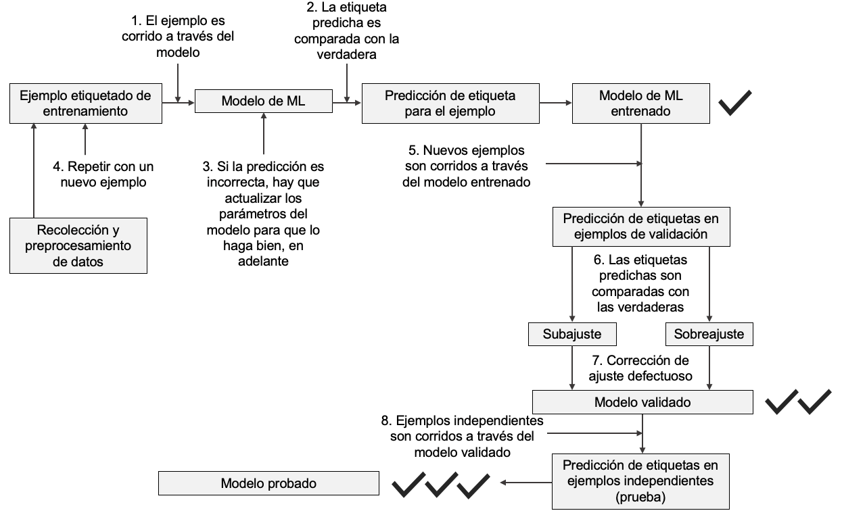
Un artículo debería describir cómo se entrenó el modelo, cómo se validó, si ocurrió sub- o sobreajuste, si se corrigió, si se realizó ajuste fino y cómo esto afectó el rendimiento del modelo, y si el modelo se puso a prueba con un conjunto de datos independiente.

4. Métricas de desempeño: ¿Qué tan bien funciona el modelo?
El cuarto paso es revisar las métricas de desempeño del modelo, tales como la precisión, sensibilidad, especificidad, AUC-ROC, F1-score, entre otras. Estas métricas reflejan qué tan bien el modelo cumple su tarea, evaluando su capacidad de generalizar a nuevos datos. Las métricas deben ser presentadas tanto para los datos de validación (utilizados para ajustar el modelo durante su desarrollo) como para los datos de prueba independientes (usados para evaluar su rendimiento real). Además, es esencial considerar cómo estas métricas se comparan con otros modelos, métodos previamente utilizados o estándares de referencia.

Resumen:
Un set mínimo efectivo de preguntas que el lector debe responder al leer un artículo de IA/ML en salud se resume en la figura 2.
Conclusiones:
Aplicar una estrategia ordenada y completa puede contribuir a la lectura comprensiva de artículos de investigación en salud que utilicen IA/ML y al hacerlo el lector podrá evaluar más críticamente sus desarrollos y su relevancia clínica.
Declaración de uso de Inteligencia artificial: ChatGPT fue utilizado para esquematizar y ordenar el manuscrito, así como para editar su texto.
Bibliografía recomendada
- Rajkomar, Alvin et al. “Machine Learning in Medicine.” The New England Journal of Medicine 380 (2019): 1347–1358.
- Sidey-Gibbons, Jenni A M, and Chris J Sidey-Gibbons. “Machine learning in medicine: a practical introduction.” BMC medical research methodology vol. 19,1 64. 19 Mar. 2019, doi:10.1186/s12874-019-0681-4
- Koteluk, Oliwia et al. “How Do Machines Learn? Artificial Intelligence as a New Era in Medicine.” Journal of personalized medicine vol. 11,1 32. 7 Jan. 2021, doi:10.3390/jpm11010032
- Liu, Yun et al. “How to Read Articles That Use Machine Learning: Users’ Guides to the Medical Literature.” JAMA vol. 322,18 (2019): 1806-1816. doi:10.1001/jama.2019.16489
- Nazha, Aziz et al. “How I read an article that uses machine learning methods.” Blood advances vol. 7,16 (2023): 4550-4554. doi:10.1182/bloodadvances.2023010140
- Cho, Hunyong et al. “Machine Learning and Health Science Research: Tutorial.” Journal of medical Internet research vol. 26 e50890. 30 Jan. 2024, doi:10.2196/50890
