Luis Eduardo Pino V. MD, M.Sc, MBA. Fundador de AIpocrates, Fundador y CEO OxLER
Demos continuidad a la primera parte de esta columna, donde abordamos la IA generativa y el Procesamiento de Lenguaje Natural (https://aipocrates.blog/2024/10/06/medicina-generativa-la-cognicion-hibrida-en-oncologia-parte-1/). En 2017, surgió una nueva arquitectura informática que, como su nombre lo indica, transformó el mundo del NLP: los transformadores, los cuales se detallarán a continuación.
¿Qué tienen que ver los Transformers en esto?
Los Transformers revolucionaron el espacio de NLP al superar las limitaciones de los modelos basados en redes neuronales profundas, esto mediante algunos conceptos nuevos:
- Mecanismo de Atención: Los Transformers introdujeron el concepto de «atención», que permite al modelo ponderar la importancia de diferentes partes de la entrada al generar la salida. Este mecanismo resuelve eficazmente el problema de la dependencia a largo plazo.
- Paralelización: A diferencia de las RNN y las LSTM, los Transformers procesan todos los puntos de datos en la secuencia de entrada de manera concurrente, lo que permite una paralelización eficiente y acelera los tiempos de entrenamiento.
- Escalabilidad: Los Transformers pueden manejar secuencias de datos más grandes de manera más efectiva que sus predecesores, lo que los hace más escalables para tareas de NLP a gran escala.
- Mejor Rendimiento: Con estas características, los Transformers han demostrado un rendimiento superior en una variedad de tareas de NLP, como traducción, resumen y análisis de sentimientos.
La estructura básica de un Transformer es la siguiente:

Figura 2: Estructura Básica de un Transformador, adaptado de (2)
Estas características únicas de los Transformers los hacen aptos para aplicaciones más allá del texto y en diferentes modalidades, como imágenes, audio y video, pero esto lo logran a través de diferentes capacidades:
Procesamiento de Imágenes: Los Transformers pueden procesar imágenes tratándolas como una secuencia de píxeles o fragmentos. Esto ha dado lugar a resultados impresionantes en tareas como clasificación y generación de imágenes. Esto permite que modelos como Midjourney y DALLE-3 funcionen.
Procesamiento de Audio: En el ámbito del audio, se han utilizado Transformers para reconocimiento de voz, generación de música e incluso síntesis de audio (Vall-E o Eleven Labs).
Procesamiento de Video: Para videos, que se pueden ver como secuencias de imágenes, los Transformers pueden manejar dependencias temporales entre fotogramas, lo que permite tareas como clasificación y generación de videos.
Procesamiento Multimodal: Los Transformers pueden procesar y relacionar información entre diferentes modalidades, lo que ha dado lugar a avances en áreas como subtitulación automática y co-generación de imagen y texto (Filmora). La capacidad multimodal es algo que viene en crecimiento y se puede observarse en desarrollos como chatGPT 4.0 y Gemini.
Es crucial para los temas siguientes enfatizar en los tres componentes principales de los Transformers:
1. La Tokenización (Entrada y Salida), es decir la transformación del texto en una lista de enteros. Esto es fundamental ya que los modelos de aprendizaje automático no entienden palabras, sino que entienden números. Este es el proceso de dividir el texto en palabras individuales o subpalabras, que se llaman tokens (números). Esto suele ser el primer paso en las tuberías de procesamiento de lenguaje natural (NLP).
La oración se divide en palabras y a cada palabra se le asigna un número fijo.
2. El mecanismo de Atención que permite ponderar la importancia de diferentes palabras o elementos en una secuencia de entrada al generar una salida. Esto significa que son capaces de modelar patrones y dependencias complejas en los datos, incluidas dependencias a largo plazo.
Así que cada palabra de entrada se representa como un token. El mecanismo de atención luego calcula un peso para cada token, en función de su relevancia para el token actual. Luego, el modelo, basado en la atención en el texto dado, predice la siguiente palabra. Genera palabras una a una, como se ve en la interfaz de algunos desarrollos basados en Transformers como Bard o ChatGPT.
3. Codificador-Decodificador. El codificador procesa el texto de entrada, convirtiéndolo en una representación significativa, mientras que el decodificador genera una secuencia de salida basada en esa representación, facilitando tareas como la traducción automática, el resumen de texto y la respuesta a preguntas. Este elemento es fundamental para entender los tipos de modelos de lenguaje a gran escala (LLM) que veremos posteriormente.
¿Modelos de Lenguaje… y de gran escala?
Ya hemos hablado de las estructuras y de los conceptos necesarios para entender mejor la IAGen, ahora pasaremos al tema fundamental para la creación de las diversas especialidades de este submundo, con ello me refiero a los modelos de lenguaje a gran escala (en inglés LLMs).
Chat-GPT es solo uno de los LLMs, tal vez el más conocido en la actualidad, pero tenemos un importante número de estos modelos (casi 20.000) que están revolucionando la forma en como se ejecuta la IAGen. Estos LLMs tiene la capacidad de trabajar sobre las arquitecturas mencionadas previamente para desarrollar tareas críticas en el procesamiento del lenguaje natural desde su entendimiento hasta la generación de salidas. En resumen estas son las cuatro grandes tareas que se han optimizado con los LLMs: 5
- Entendimiento del lenguaje natural,
- Generación de lenguaje natural coherente, relevante contextualmente y de alta calidad,
- Tareas de conocimiento intensivo en dominios generales o específicos como el de la medicina y
- Capacidad de razonamiento para mejorar la gestión de las decisiones y la resolución de problemas
Las principales especificaciones de los LLM que podemos analizar para comprender su variedad son:
- Longitud del contexto: El número máximo de tokens que se pueden considerar al predecir el siguiente token. Las longitudes de contexto comúnmente disponibles son 2K y 4K. Las más grandes hasta la fecha son de aproximadamente 65K y 100K.
- Tamaño del vocabulario: El número de tokens únicos que el modelo puede entender.
- Parámetros: El número de pesos entrenables en el modelo. Esto puede estar en miles de millones o incluso billones de parámetros. Nota: La cantidad de parámetros no es un indicador de rendimiento.
- Tokens de entrenamiento: El número de tokens en los que se entrenó el modelo. Esto puede estar en cientos de miles de millones o incluso billones de tokens.
- La arquitectura, esto se refiere a si contienen tanto codificador como decodificador o solo decodificador.
La figura resume el tamaño de los LLM de acuerdo con sus datos de entrenamiento haciendo claridad que GPT4 ya fue liberado y que tiene 1,76 trillones de parámetros (1,7 T). 6
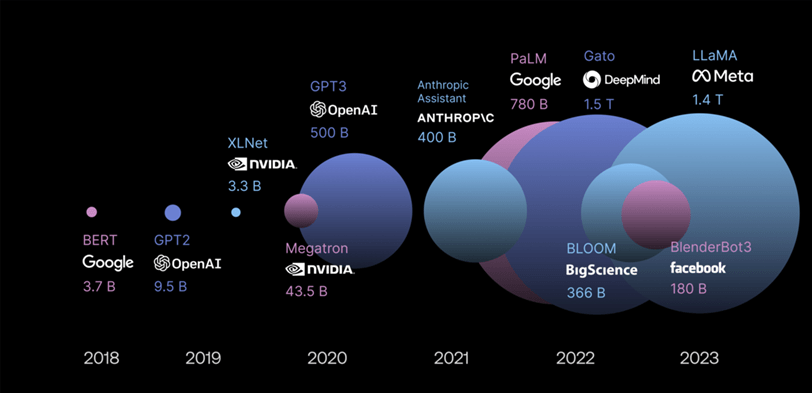
Figura 3: Tamaño en Datos de los LLM, tomado de (6)
La siguiente tabla resume la arquitectura de los LLMs y sus características principales.
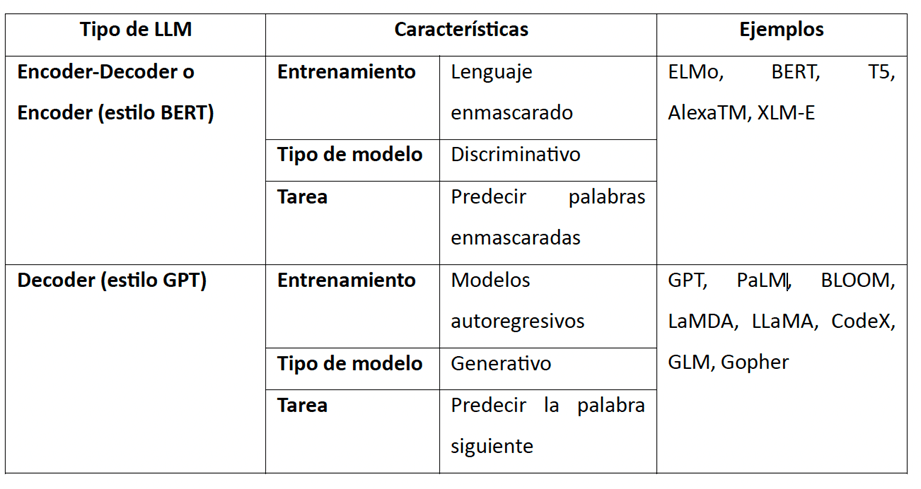
Tabla 1: Arquitectura de los LLM. Propuesta del autor
En resumen, cuando una persona genera una instrucción o prompt en un modelo como chatGPT, este texto es convertido a una estructura matemática relacional depurada mediante el mecanismo de atención del Transformer (GPT significa transformer generativo pre-entrenado). Una vez es “ingerida” la información por la arquitectura, el modelo analiza el prompt utilizando su entrenamiento previo (para GPT se trata de un entrenamiento reforzado con feedback humano o RLHF) y produce unas salidas que conectan sus datos de entrenamiento (es decir el estado del arte o SOTA) con el análisis de respuestas basados en las mejores probabilidades (búsqueda semántica).
Sin embargo, modelos como GPT 3,5 e inclusive el GPT 4.0 aún son de baja concordancia y profundidad en dominios del conocimiento de alta complejidad como las especialidades médicas, por lo tanto deben surtir un proceso de entrenamiento y ajuste fino llamado ajuste fino con parámetros eficientes (PEFT), labor que debe ser realizada por los expertos de dominio, en este caso los médicos.
Los modelos generativos como GPT en general se entrenan mediante varios procesos: 7
Pre-entrenamiento
En este paso, el modelo aprende las relaciones estadísticas entre palabras y frases. La mayor parte del trabajo de entrenamiento se realiza en esta etapa. Implica entrenar el modelo en un gran corpus de texto disponible públicamente en Internet. Requiere una gran cantidad de cómputo GPU para entrenar dichos modelos (100-1000+ GPUs). Utiliza el aprendizaje no supervisado, lo que significa que el modelo aprende a predecir la siguiente palabra en una oración, comprendiendo así la estructura del lenguaje. Como resultado, se obtiene un «modelo base» que tiene una comprensión general del lenguaje pero no tiene experiencia específica.
Modelado por recompensa
La recompensa proviene de evaluadores humanos, a quienes se les proporcionan múltiples respuestas a una sola indicación y deben puntuar cada una de ellas en función de la calidad relativa de la respuesta. El modelo se entrena para predecir la recompensa junto con el texto generado. El modelado de recompensa se puede utilizar para mejorar el rendimiento de los modelos en una variedad de tareas, como generar formatos de texto creativo, traducir idiomas y escribir diferentes tipos de contenido creativo.
Aprendizaje por refuerzo
Se utiliza en combinación con el modelado de recompensa para mejorar la capacidad del modelo de generar texto con recompensas más altas de manera consistente. Para entrenar estos modelos se utiliza una gran cantidad de datos de lenguaje. El conjunto de datos está compuesto por datos de múltiples fuentes y se llama mezcla de datos (data mixture). Ejemplo de mezcla de datos.
Ajuste fino supervisado
Esto se puede utilizar para mejorar el rendimiento del modelo pre-entrenado en una tarea específica. Requiere datos de baja cantidad pero alta calidad. Con el enfoque de ajuste fino supervisado, se puede introducir la capacidad de participar en un diálogo o chat en un modelo base. Las técnicas de ajuste fino permiten disminuir las llamadas “alucinaciones” de los modelos o las pérdidas de información (salidas falsas). Hay esencialmente tres grandes técnicas para ello, las cuales van desde la básica ingeniería de prompts (ajustar las instrucciones al modelo para que genere salidas más exactas) hasta recuperación aumentada (RAG) y el previamente mencionado PEFT.
La recuperación implica encontrar datos relevantes de un conjunto de datos grande. En los modelos de lenguaje, la recuperación encuentra texto similar utilizando bases de datos vectoriales. Estas bases de datos almacenan vectores y utilizan técnicas como indexación, medidas de similitud y búsqueda aproximada para una recuperación eficiente. Por ejemplo, para encontrar texto relacionado con «inteligencia artificial», una base de datos vectorial indexaría el conjunto de datos, calcularía distancias de similitud y devolvería vectores similares. La recuperación con bases de datos vectoriales mejora la velocidad y precisión de búsqueda y recuperación para varios tipos de datos como texto e imágenes.
El ajuste fino de los LLM, especialmente el PEFT se puede utilizar para adaptarlos a cualquier caso de uso personalizado. Es en este campo en donde los oncólogos pueden apoyar el proceso utilizando su experiencia y conocimiento contextual como un activo no tangible. Hoy la medicina no es una ciencia de contenido sino de procesamiento de conocimiento.
En el contexto de la oncología, la inteligencia artificial generativa ha mostrado un potencial extraordinario para transformar cómo entendemos, diagnosticamos y tratamos el cáncer. Su aplicación va desde la identificación precisa de biomarcadores y la generación de nuevas hipótesis sobre las causas y mecanismos del cáncer, hasta la personalización de tratamientos basados en la genética y las características individuales de cada paciente. Además, la IA generativa puede mejorar significativamente la eficiencia y precisión de la interpretación de imágenes médicas, permitiendo una detección más temprana y precisa de tumores y metástasis.
Los asistentes virtuales de salud, potenciados por la IA generativa, pueden ofrecer a los pacientes oncológicos un soporte constante y personalizado, ayudándoles a gestionar sus tratamientos y efectos secundarios, y ofreciendo respuestas inmediatas a sus inquietudes. Esto no solo mejora la calidad de vida de los pacientes, sino que también les empodera para ser participantes activos en su propio cuidado. Pronto, la evolución de agentes generativos a agentes autónomos permitirán entregar contenidos personalizados y realización de tareas secuenciales.
Los tres grandes campos en donde la IAGen tiene ámbito de aplicación son: flujos clínicos (asistente cognitivo para los sistemas de soporte al razonamiento clínico), educación médica y empoderamiento de pacientes e investigación (incluyendo el desarrollo de fármacos). 7,8
Un ejemplo aplicado localmente es Nova, un agente generativo conversacional entrenado por OxLER en alianza con Ghenova Digital y que actúa como un sistema de soporte al razonamiento clínico pero también como un sistema de empoderamiento de la enfermedad para pacientes y cuidadores, específicamente en el campo de la oncología torácica, con un nivel de profundidad que va hasta el oncólogo general y que podría aportar en modelos de telesalud/teleapoyo. Actualmente se encuentra en fase de validación clínica y entrenamiento adicional en otras neoplasias. El demo puede verse en el siguiente código QR:

No obstante, la implementación de la IA generativa en oncología también enfrenta desafíos significativos, incluyendo cuestiones éticas relacionadas con la privacidad de los datos y el consentimiento informado, la necesidad de validar clínicamente las herramientas de IA para asegurar su eficacia y seguridad, y la importancia de garantizar la equidad en el acceso a estas tecnologías avanzadas.
Para maximizar los beneficios de la IA generativa en oncología, es crucial la colaboración multidisciplinaria entre oncólogos, investigadores, desarrolladores de IA, pacientes y reguladores. Esta colaboración facilitará no solo la innovación responsable, sino también la implementación efectiva de soluciones de IA que puedan mejorar significativamente los resultados de los pacientes, ofrecer tratamientos más personalizados y acelerar los avances en la investigación contra el cáncer. Así, la IA generativa se erige como una herramienta poderosa en la lucha contra el cáncer, prometiendo transformar el futuro de la oncología y mejorar la vida de los pacientes a nivel global.
Referencias
1. Morris AH. Human Cognitive Limitations. Broad, Consistent, Clinical Application of Physiological Principles Will Require Decision Support. Ann Am Thorac Soc. 2018 Feb;15(Suppl 1):S53-S56. doi: 10.1513/AnnalsATS.201706-449KV. PMID: 29461892; PMCID: PMC5822395)
2. Vasmani A et al. Attention Is All You Need. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. 1-15.
3. Nuance Communications. [Internet]. [citado 2024 Feb 10]. Disponible en: https://www.nuance.com/index.html.
4. Gu A, Dao T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752 [Preprint]. 2023 Dec [cited 2024 Feb 10]. Available from: https://arxiv.org/abs/2312.00752.
5. Agarwal V, et al. «Which LLM should I use?»: Evaluating LLMs for tasks performed by Undergraduate Computer Science Students in India. In: Proceedings of the ITiCSE 2024; 2024 Jul 08–10; Milan, Italy.
6. Data Science 101. What are LLMs – Part 1. [citado 2024 Feb 10]. Disponible en: https://datasci101.com/what-are-llms-part-1/.
7. Thirunavukarasu A et al. Large Language Models in Medicine. Nature Medicine 2023. https://doi.org/10.1038/s41591-023-02448-8.
8. Chen S et al. Evaluation of chatGPT family of models for Biomedical Reasoning and Classification. arXiv preprint arXiv:2304.02496, 2023.
