Luis Eduardo Pino Villarreal MD; M.Sc; MBA
Fundador de AIpocrates – CEO Oxler
Las grandes disrupciones marcan momentos de la historia que nunca olvidaremos, algunos por su impacto masivo como los ataques del 11 de septiembre de 2001, los cuales redefinieron el terrorismo mundial y trazaron un nuevo rumbo geopolítico, otros derivados de ideas que han cambiado el mundo como el descubrimiento del fuego, la invención del cálculo o la internet.
En noviembre de 2022 la aparición del desarrollo informático llamado chatGPT desarrollado por la empresa openAI trajo a la luz un nuevo concepto: el de la Inteligencia Artificial Generativa (IAGen).
En esta serie de columnas hablaremos sobre la intersección entre la IAGen y la medicina. Pero para ello debemos primero explorar su fantástica anatomía y fisiología. ¡Bienvenidos!
Introducción a la Medicina Generativa
Ruego al lector no confundir el término con el de medicina regenerativa que tiene un contexto enfocado en el uso de tecnologías para la reparación, regeneración y reemplazo de tejidos y órganos dañados o enfermos.
La Inteligencia Artificial Generativa (IA generativa) ha comenzado a abrir nuevas posibilidades en el campo de la medicina, trascendiendo el ámbito de las conversaciones automatizadas de ChatGPT. Estos avances tecnológicos están revolucionando la forma en que se abordan los desafíos médicos, permitiendo a los profesionales de la salud explorar y desarrollar soluciones innovadoras y personalizadas.
La IA generativa en medicina se basa en la capacidad de los modelos de IA para aprender de grandes cantidades de datos y generar contenido nuevo y valioso en el contexto médico. Estos modelos pueden analizar y comprender información clínica, investigaciones científicas, historiales médicos y otros datos relevantes para proporcionar diagnósticos más precisos, pronósticos personalizados y opciones de tratamiento optimizadas.
A medida que la tecnología avanza, la medicina generativa también se está utilizando para mejorar la investigación biomédica y el desarrollo de medicamentos. Los modelos de IA pueden ayudar en la identificación de nuevas moléculas farmacéuticas, predecir la eficacia de ciertos tratamientos y acelerar el proceso de descubrimiento de diversas tecnologías.
En columnas posteriores exploraremos cómo la medicina generativa está transformando el panorama de la atención médica, superando el simple concepto de las conversaciones con ChatGPT y allanando el camino hacia una medicina más precisa, personalizada y eficiente. Descubriremos los avances más recientes, las aplicaciones prácticas y las perspectivas futuras de esta fascinante convergencia entre la inteligencia artificial y la medicina.
Estamos sin duda en la era de la Medicina Generativa y en camino hacia la IA general en salud.
¿Por Qué IA Generativa?
El campo de la inteligencia artificial generativa ha estado evolucionando rápidamente en los últimos años, con varios actores importantes en la industria y la comunidad de código abierto liderando el camino en la realización de grandes avances. Estos avances han dado lugar a nuevas posibilidades y aplicaciones para la inteligencia artificial generativa, como en los campos del procesamiento del lenguaje natural, la visión por computadora y la generación de música. Además, la creciente disponibilidad de datos y potencia de cálculo ha permitido desarrollar modelos más complejos y sofisticados, lo que abre aún más el potencial para la inteligencia artificial generativa en el futuro. A medida que este campo continúe creciendo y desarrollándose, será emocionante ver qué nuevos avances surgirán y cómo darán forma a nuestro mundo.
Hoy tenemos dos grandes campos de la IA: la IA Analítica o IA clásica, que se refiere al uso de máquinas para analizar datos existentes e identificar patrones o hacer predicciones para diversas aplicaciones como detección de fraudes o recomendaciones de contenido, esto a través de los diversos tipos de entrenamiento (supervisado, no supervisado, reforzado, semisupervisado etc). Es decir que la IA clásica se centra en analizar y procesar la información disponible. Por otro lado, la IA Generativa es un campo que implica que las máquinas generen nuevos datos, como imágenes, texto o música, basados en patrones y modelos aprendidos. Para facilitar la comprensión veamos algunos ejemplos:
- IA clásica: Supongamos que tenemos un conjunto de datos de transacciones financieras del sistema de salud. Utilizando algoritmos de IA analítica podemos analizar esos datos para identificar patrones y detectar anomalías que puedan indicar actividades fraudulentas o extremos. Esto puede ayudar al sistema de salud a encontrar posibles fraudes y tomar medidas preventivas.
- IA Generativa: Si entrenamos a un modelo de IA generativa con millones de estructuras proteicas como AlphaFold2 y posteriormente le introducimos instrucciones (o prompts, en adelante) podríamos generar modelos sintéticos de moléculas de diversa indole para su posterior desarrollo.
La inteligencia artificial generativa NO es nueva, ha estado en desarrollo durante algún tiempo, pero en los últimos años, todo el ecosistema de la IA generativa ha experimentado un desarrollo significativo. Sin embargo, para comprender completamente el estado actual de los acontecimientos y apreciar el potencial completo de la IA generativa, es importante adentrarse en los avances realizados en el campo del procesamiento del lenguaje natural (NLP). El surgimiento de los modelos transformadores o Transformers ha desempeñado un papel crucial en este sentido. A través del uso de transformadores, la IA ahora puede procesar y generar lenguaje, imágenes y videos, y trabajar en múltiples modalidades combinadas.
Procesamiento de Lenguaje Natural, ¿cómo así?
El procesamiento de lenguaje natural (NLP) es una rama de la inteligencia artificial que se ocupa de la interacción entre las computadoras y el lenguaje humano. Su objetivo es permitir que las computadoras comprendan, analicen y generen lenguaje humano de manera efectiva.
El lenguaje humano es complejo y diverso, y el PLN abarca una amplia gama de tareas para procesar y comprender el lenguaje. Algunas de estas tareas incluyen (estos conceptos son de crucial importancia):
- Tokenización: Dividir el texto en unidades más pequeñas, como palabras o subpalabras, para su análisis posterior. El texto y las imágenes son susceptibles de transformar en estructuras matemáticas para poderlas introducir a los lenguajes de programación.
- Análisis morfológico: Identificar la estructura y forma de las palabras, incluyendo raíces, prefijos y sufijos.
- Análisis sintáctico: Determinar la estructura gramatical de una oración y las relaciones entre las palabras.
- Análisis semántico: Comprender el significado de las oraciones y las palabras, incluyendo la interpretación de la intención y el contexto.
- Desambiguación: Resolver ambigüedades en el lenguaje, como la polisemia (palabras con múltiples significados) y la correferencia (referencia a entidades previamente mencionadas).
- Generación de lenguaje natural: Crear texto coherente y comprensible para comunicarse con los usuarios.
El NLP se aplica en una amplia variedad de campos como traducción automática, análisis de sentimientos, chatbots, asistentes virtuales, resumen automático de texto, extracción de información, clasificación de texto y muchas más. Gracias al NLP por ejemplo tenemos hoy algunas historias clínicas electrónicas que anticipan texto y automatizan registros.
Para resolver eficazmente los problemas en el espacio de NLP, existen diversos desafíos:
- Complejidad del Lenguaje Natural: El lenguaje humano es sutil, ambiguo y dependiente del contexto. Por lo tanto, plantea un desafío significativo para los modelos de aprendizaje automático para comprender y generar texto coherente y significativo.
- Problema de Dependencia Larga: En muchos casos, el significado de una oración o una frase depende en gran medida del contexto establecido mucho antes en el texto. Los modelos de NLP tradicionales tienen dificultades para mantener y comprender estas dependencias a largo plazo.
- Escalabilidad: El procesamiento de texto a gran escala requiere recursos computacionales significativos, lo que dificulta escalar los sistemas de NLP tradicionales para tareas más grandes.
- Falta de Generalización: A menudo, los modelos tienen dificultades para generalizar su comprensión del lenguaje en diferentes tareas, géneros e idiomas.
- Limitación de los modelos RNN y LSTM: Durante mucho tiempo se utilizaron modelos de Deep learning como las Redes Neuronales Recurrentes (RNN) y los modelos de Memoria a Corto y Largo Plazo (LSTM), que alguna vez fueron fundamentales para las tareas de NLP, pero tienen limitaciones, especialmente su procesamiento secuencial, alto recurso computacional, gradiente desvaneciente (no entraré en detalles en este tema técnico) que limita el análisis de las dependencias mencionadas previamente y la dificil adaptación a la computación paralela, es decir a usar recursos modernos de hardware.
En el año 2017 aparece entonces una arquitectura que -como su nombre lo indica- transformó el mundo de NLP, este fue el de los Transformadores (el icónico artículo “Attention is all you need” del grupo Google Deepmind).
¿Qué tienen que ver los Transformers en esto?
Los Transformers revolucionaron el espacio de NLP al superar las limitaciones de los modelos basados en RNN y LSTM mediante algunos conceptos nuevos:
- Mecanismo de Atención: Los Transformers introdujeron el concepto de «atención», que permite al modelo ponderar la importancia de diferentes partes de la entrada al generar la salida. Este mecanismo resuelve eficazmente el problema de la dependencia a largo plazo.
- Paralelización: A diferencia de las RNN y las LSTM, los Transformers procesan todos los puntos de datos en la secuencia de entrada de manera concurrente, lo que permite una paralelización eficiente y acelera los tiempos de entrenamiento.
- Escalabilidad: Los Transformers pueden manejar secuencias de datos más grandes de manera más efectiva que sus predecesores, lo que los hace más escalables para tareas de NLP a gran escala.
- Mejor Rendimiento: Con estas características, los Transformers han demostrado un rendimiento superior en una variedad de tareas de NLP, como traducción, resumen y análisis de sentimientos.
La estructura básica de un Transformer es la siguiente:
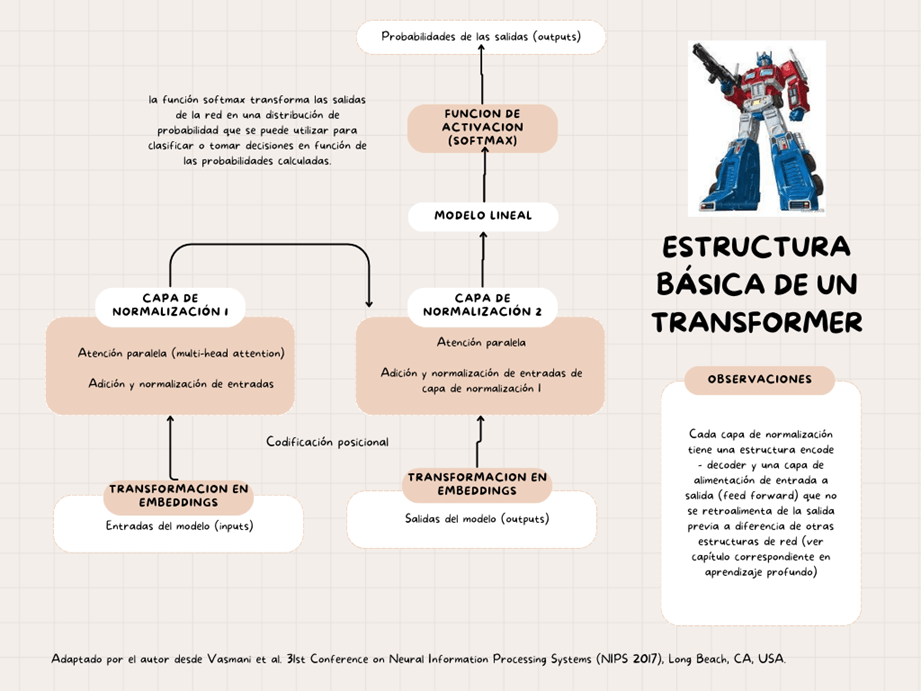
Estas características únicas de los Transformers los hacen aptos para aplicaciones más allá del texto y en diferentes modalidades, como imágenes, audio y video, pero ¿cómo lo hacen?
Procesamiento de Imágenes: Los Transformers pueden procesar imágenes tratándolas como una secuencia de píxeles o fragmentos. Esto ha dado lugar a resultados impresionantes en tareas como clasificación y generación de imágenes (ver modelos como Midjourney o Leonardo.ai)
Procesamiento de Audio: En el ámbito del audio, se han utilizado Transformers para reconocimiento de voz, generación de música e incluso síntesis de audio (ver modelos como Vall-E o Eleven Labs).
Procesamiento de Video: Para videos, que se pueden ver como secuencias de imágenes, los Transformers pueden manejar dependencias temporales entre fotogramas, lo que permite tareas como clasificación y generación de videos.
Procesamiento Multimodal: Los Transformers pueden procesar y relacionar información entre diferentes modalidades, lo que ha dado lugar a avances en áreas como subtitulación automática y co-generación de imagen y texto (ver Filmora).
Es crucial para los temas siguientes enfatizar en 3 componentes principales de los Transformers:
1. La Tokenización (Entrada y Salida), es decir la transformación del texto en una lista de enteros. Esto es fundamental ya que los modelos de aprendizaje automático no entienden palabras, sino que entienden números. Este es el proceso de dividir el texto en palabras individuales o subpalabras, que se llaman tokens (números). Esto suele ser el primer paso en las tuberías de procesamiento de lenguaje natural (NLP).
La oración se divide en palabras y a cada palabra se le asigna un número fijo.
2. El mecanismo de Atención que permite ponderar la importancia de diferentes palabras o elementos en una secuencia de entrada al generar una salida. Esto significa que son capaces de modelar patrones y dependencias complejas en los datos, incluidas dependencias a largo plazo.
Así que cada palabra de entrada se representa como un token. El mecanismo de atención luego calcula un peso para cada token, en función de su relevancia para el token actual. Luego, el modelo, basado en la atención en el texto dado, predice la siguiente palabra. Genera palabras una a una, como se ve en la interfaz de algunos desarrollos basados en Transformers como Bard o ChatGPT.
3. Codificador-Decodificador. El codificador procesa el texto de entrada, convirtiéndolo en una representación significativa, mientras que el decodificador genera una secuencia de salida basada en esa representación, facilitando tareas como la traducción automática, el resumen de texto y la respuesta a preguntas. Este elemento es fundamental para entender los tipos de modelos de lenguaje a gran escala (LLM) que veremos posteriormente.
¿Modelos de Lenguaje… y de gran escala?
Ya hemos hablado de las estructuras y los conceptos necesarios para entender mejor la IAGen, ahora pasaremos al tema fundamental para la creación de las diversas especialidades de este submundo, con ello me refiero a los modelos de lenguaje a gran escala (en inglés LLMs).
Chat-GPT es solo uno de los LLMs, tal vez el más conocido en la actualidad, pero tenemos un importante número de estos modelos que están revolucionando la forma en como se ejecuta la IAGen. Estos LLMs tiene la capacidad de trabajar sobre las arquitecturas mencionadas previamente para desarrollar tareas críticas en el procesamiento del lenguaje natural desde su entendimiento hasta la generación de salidas. En resumen estas son las cuatro grandes tareas que se han optimizado con los LLMs:
- Entendimiento del lenguaje natural,
- Generación de lenguaje natural coherente, relevante contextualmente y de alta calidad,
- Tareas de conocimiento intensivo en dominios generales o específicos como el de la medicina y
- Capacidad de razonamiento para mejorar la gestión de las decisiones y la resolución de problemas
Las principales especificaciones de los LLMs que podemos analizar para comprender su variedad son:
- Longitud del contexto: El número máximo de tokens que se pueden considerar al predecir el siguiente token. Las longitudes de contexto comúnmente disponibles son 2K y 4K. Las más grandes hasta la fecha son de aproximadamente 65K y 100K.
- Tamaño del vocabulario: El número de tokens únicos que el modelo puede entender.
- Parámetros: El número de pesos entrenables en el modelo. Esto puede estar en miles de millones o incluso billones de parámetros. Nota: La cantidad de parámetros no es un indicador de rendimiento.
- Tokens de entrenamiento: El número de tokens en los que se entrenó el modelo. Esto puede estar en cientos de miles de millones o incluso billones de tokens.
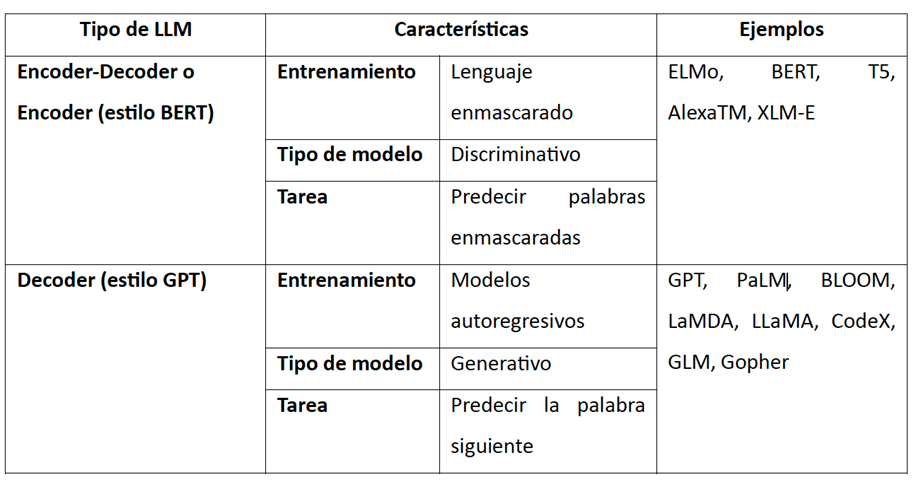
- La arquitectura, esto se refiere a si contienen tanto codificador como decodificador o solo decodificador (ver modelos generativos en medicina en www.consultorsalud.com y www.aipocrates.org).
La imagen resume el tamaño de los LLMs de acuerdo con sus datos de entrenamiento haciendo claridad que GPT4 ya fue liberado y que tiene 175 billones de parámetros.

La siguiente tabla resume la arquitectura de los LLMs y sus características.
En resumen, cuando una persona genera una instrucción o prompt en un modelo como chatGPT, este texto es convertido en una estructura matemática relacional depurada mediante el mecanismo de atención del transformer (GPT significa transformer generativo pre-entrenado, leer detalles en ¡what the chatGPT! en www.consultorsalud.com y www.aipocrates.org).
Una vez es “ingerida” la información por la arquitectura, el modelo analiza el prompt utilizando su entrenamiento previo (para GPT se trata de un entrenamiento reforzado con feedback humano o RLHF) y produce unas salidas que conectan sus datos de entrenamiento (es decir el estado del arte o SOTA) con el análisis de respuestas basados en las mejores probabilidades.
Como veremos en columnas posteriores, modelos como GPT 3,5 e inclusive el 4.0 aún son de baja concordancia y profundidad en dominios del conocimiento de alta complejidad como las especialidades médicas, por lo tanto deben surtir un proceso de entrenamiento y ajuste fino que detallaremos en su momento.
Los esperamos en las siguientes columnas para entender como los médicos e informáticos en colaboración podemos optimizar, entrenar y utilizar los modelos generativos para nuestras necesidades, más allá de ser solamente sus usuarios.
