Alejandro Hernández-Arango MD MS. Profesor UdeA, Internista, Informática Médica Hospital Alma Máter
Sección 2: La alternativa de código abierto: un camino hacia el control de datos
En marcado contraste con los riesgos y las dependencias asociadas a los LLM comerciales de código cerrado, el movimiento de código abierto ofrece una alternativa convincente para las organizaciones de salud que buscan mantener el control sobre sus datos y su destino tecnológico. Al permitir la implementación local y proporcionar una transparencia sin precedentes, los modelos de código abierto representan una vía viable para lograr una verdadera soberanía de los datos. Sin embargo, esta vía no está exenta de importantes desafíos técnicos y económicos.
2.1 La promesa de la implementación local: beneficios de la implementación local y transparencia del modelo
La principal y más significativa ventaja de los LLM de código abierto es la posibilidad de implementarlos en el entorno seguro de la institución. Esto puede ser local, utilizando los servidores del hospital, o en una instancia de nube privada dedicada. Esta única opción arquitectónica modifica radicalmente el cálculo de riesgos.
- Control absoluto de datos y privacidad: Cuando un modelo de código abierto se ejecuta localmente, los datos confidenciales de los pacientes nunca tienen que salir del perímetro de red de confianza de la institución. Todo el procesamiento de las solicitudes y la generación de respuestas se realiza internamente, eliminando los riesgos de transferencia de datos inherentes al envío de datos privados de salud a una API de terceros en la nube. Esto proporciona a la organización un control total e inequívoco sobre todo el ciclo de vida de los datos y representa una postura fundamentalmente más segura. Es un enfoque muy atractivo para los directores de sistemas de información (CIO) de hospitales, los responsables de cumplimiento normativo y los médicos, quienes, con razón, se preocupan por la posibilidad de que los datos escapen de su control.
- Mayor transparencia y auditabilidad: Un modelo de IA que sea verdaderamente de código abierto implica compartir no solo las ponderaciones finales del modelo, sino también el código fuente e, idealmente, información sobre los datos de entrenamiento, todo ello bajo una licencia permisiva. Este nivel de transparencia abre la «caja negra» del modelo de IA. Permite auditorías de seguridad independientes, evaluaciones de sesgos y validación algorítmica por parte de los propios expertos de la institución o de terceros de confianza. Esta capacidad de analizar el funcionamiento interno del modelo es imposible con sistemas cerrados y propietarios, y es crucial para generar confianza entre profesionales clínicos, pacientes y organismos reguladores.
- Personalización y extensibilidad sin precedentes: Los modelos de código abierto ofrecen a las organizaciones de salud la capacidad de ajustar y modificar la IA para adaptarla a sus necesidades específicas. Una institución puede perfeccionar un modelo de código abierto de propósito general utilizando sus propios datos locales anonimizados. Esto permite adaptar el modelo a la demografía específica de su población de pacientes, sus protocolos clínicos únicos o sus objetivos de investigación particulares. Este proceso puede conducir a la creación de herramientas de IA altamente especializadas, más precisas y relevantes que las que un modelo propietario genérico y universal podría proporcionar.
- Eliminación de la dependencia del proveedor y del riesgo de políticas: Al invertir en la capacidad de autoalojar modelos de código abierto, una institución se libera de la dependencia de un único proveedor comercial. Esta independencia estratégica protege a la organización de los riesgos de aumentos repentinos de precios, cambios desfavorables en las condiciones de servicio, la interrupción de una API específica o la volatilidad de políticas que se observa en empresas como Anthropic. Proporciona estabilidad a largo plazo y permite a la organización controlar su propia hoja de ruta tecnológica.
2.2 Cerrando la brecha de rendimiento: el auge de los modelos competitivos de código abierto
Durante años, el principal argumento a favor del uso de LLM propietarios fue su rendimiento superior. Sin embargo, el ritmo de innovación en la comunidad de código abierto ha sido asombroso, y la evidencia reciente, revisada por pares, demuestra que esta brecha de rendimiento se ha reducido significativamente y, en algunos casos, se ha eliminado o incluso revertido.
La idea de que el código abierto implica sacrificar la calidad se está volviendo rápidamente obsoleta. Un estudio histórico de 2025 dirigido por investigadores de la Facultad de Medicina de Harvard y publicado en JAMA Se realizó una comparación directa de un modelo líder de código abierto, Llama 3.1 405B, con el GPT-4 de OpenAI. Se probó la capacidad de los modelos para diagnosticar casos clínicos con diagnóstico complejo tomados de NEJM. Los resultados fueron sorprendentes: el modelo de código abierto funcionó al mismo nivel que su contraparte propietaria y, en algunas métricas, incluso la superó.
- En el estudio, Llama logró un diagnóstico final correcto en el 70% de los casos, en comparación con el 64% para GPT-4.
- Para evaluar la capacidad de razonamiento genuina, en lugar de la simple memorización de casos publicados, los investigadores incluyeron un subconjunto de 22 casos nuevos publicados después del corte de datos de entrenamiento de Llama. Con estos datos no vistos, el rendimiento de Llama fue aún mejor, con una tasa de precisión del 73 %.
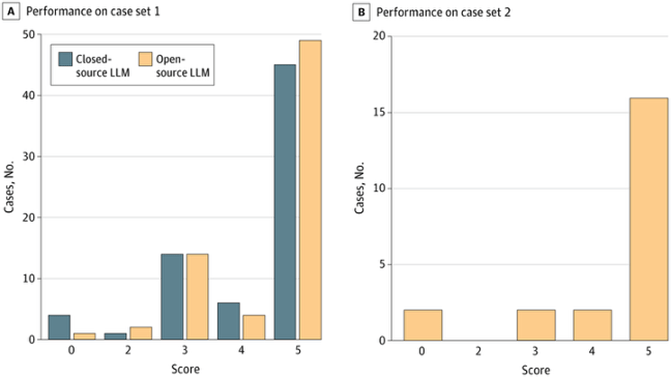
Performance of 2 Large Language Models (LLMs) on Complex Diagnostic Challenges Histogram comparison of differential diagnosis quality by the GPT-4 (Generative Pre-trained Transformer 4) model (closed-source LLM) and the 405-billion parameter Llama 3.1 model (open-source LLM) using the quality score metric on case set 1 (A) and case set 2 (B). The scoring used is a version adapted by Kanjee et al from the original in Bond et al (the original assigned inversely to the one presented here). The scale used is as follows: 5 = the actual diagnosis was suggested in the differential; 4 = the suggestions included something very close, but not exact; 3 = the suggestions included something closely related that might have been helpful; 2 = the suggestions included something related, but unlikely to be helpful; and 0 = no suggestions close to the target diagnosis JAMA Health Forum. 2025;6(3):e250040. doi:10.1001/jamahealthforum.2025.0040
Esta tendencia es visible en todo el campo. En parámetros académicos estandarizados de conocimiento médico, como MedQA (que utiliza preguntas del Examen de Licencia Médica de EE. UU.) y PubMedQA, los modelos de código abierto de mayor rendimiento, como OpenBioLLM-Llama3-70B, superan regularmente a gigantes de la tecnología propietaria como GPT-4 y Med-PaLM-2 de Google. Esto indica que, para tareas de conocimiento y razonamiento médico bien definidas, la comunidad de código abierto ha alcanzado un rendimiento de vanguardia.
La utilidad práctica de estos modelos se extiende también a tareas de salud especializadas. Un estudio demostró que los LLM de código abierto, más pequeños y gestionados localmente (como LLaMA y Alpaca), podían utilizarse eficazmente para la ampliación de datos. Generaron datos sintéticos para ampliar un pequeño conjunto de datos reales de encuestas al personal hospitalario, lo que a su vez mejoró significativamente el rendimiento de un modelo de clasificación de texto. Todo este proceso se llevó a cabo internamente, lo que mitigó los riesgos de privacidad y los altos costes que lo habrían hecho inviable con una API comercial de terceros.
Esta rápida recuperación del rendimiento indica una mercantilización de las capacidades esenciales de la IA avanzada. El secreto de los modelos propietarios ya no representa una ventaja competitiva insalvable. Esto transforma fundamentalmente el proceso de toma de decisiones de las organizaciones de salud. Cuando el rendimiento deja de ser un factor decisivo, otros atributos, como la privacidad, el control y el coste, se vuelven primordiales. El debilitamiento del argumento a favor de la superioridad de los modelos propietarios hace que los profundos beneficios de la soberanía de datos del enfoque de código abierto sean mucho más convincentes.
2.3 El alto costo del control: análisis técnico y económico del autoalojamiento
Si bien los beneficios de los LLM de código abierto son evidentes, el camino hacia su implementación presenta importantes obstáculos financieros y técnicos. El control que ofrece el autoalojamiento tiene un alto coste, lo que crea una importante barrera para su adopción, especialmente para instituciones con recursos limitados.
El desafío más inmediato es el Costo prohibitivo del hardware y la infraestructura para operar LLM modernos y de alto rendimiento, las organizaciones requieren una inversión sustancial en hardware especializado, principalmente servidores GPU de alta gama. Los análisis de costos reales compartidos por desarrolladores en foros profesionales presentan un panorama desolador:
- Ejecutar un modelo de 70 mil millones de parámetros de nivel de producción como Llama-3 en la infraestructura de un importante proveedor de nube (por ejemplo, una instancia AWS p4d.24xlarge) puede costar más de $287,000 USD por año para un único servidor que funciona 24 horas al día, 7 días a la semana.
- Incluso modelos más pequeños, pero aún potentes, de 32 mil millones de parámetros pueden generar costos de infraestructura en la nube de alrededor de$50,000USD por año Si bien comprar y ubicar hardware físico en un centro de datos puede ser más rentable a largo plazo que alquilar instancias en la nube, esta estrategia requiere una enorme inversión inicial y una profunda experiencia técnica en la gestión de centros de datos.
Más allá del hardware, existe la complejidad operativa de gestionar el propio modelo de IA. Este es un campo especializado conocido como LLMOps (Operaciones de modelos de lenguaje grandes) Una organización que se autoaloja es responsable de todo el ciclo de vida del modelo: implementación inicial, monitoreo continuo, escalamiento para satisfacer la demanda, mantenimiento y actualizaciones regulares, y ajustes para tareas específicas. Esto requiere un equipo dedicado de ingenieros altamente capacitados (y costosos) con experiencia en aprendizaje automático, administración de infraestructura y ciberseguridad. Esta carga operativa representa un costo continuo significativo y a menudo subestimado.
Tabla 1: Análisis comparativo de los riesgos de privacidad en los LLM comerciales y de código abierto
| Vector de características/riesgos | LLM comerciales de código cerrado (API de OpenAI, Anthropic) | LLM de código abierto autoalojados (por ejemplo, Llama 3, Mistral) |
| Residencia y control de datos | Datos (solicitudes, datos privados de salud) enviados a servidores externos de terceros. El control está sujeto a las políticas del proveedor y los acuerdos de asociación comercial (BAA). | Los datos permanecen dentro de la infraestructura segura de la institución (local o en la nube privada). Control total sobre el ciclo de vida de los datos. |
| Riesgo de exfiltración de datos | Alto. Vulnerable a memorización involuntaria, inferencia de membresía y ataques de inversión de modelo por parte de actores externos o del proveedor. | Bajo. La superficie de ataque se limita a la seguridad de la red de la institución. No hay riesgo de fugas de información del proveedor. |
| Transparencia del modelo | Una «caja negra» opaca. Los datos de entrenamiento, los algoritmos y el procesamiento interno no son auditables. | Alto. El código fuente, los pesos del modelo y, a menudo, los datos de entrenamiento están disponibles públicamente para inspección y auditoría. |
| Política y estabilidad de salvaguardias | Volátil. Las políticas de privacidad y las medidas de seguridad pueden cambiar sin previo aviso, lo que crea un modelo de amenaza «vivo». | Estable. La institución controla la versión del modelo y cualquier actualización. Sin cambios inesperados en las políticas por parte de un proveedor externo. |
| Cumplimiento de HIPAA | Complejo. Se basa en acuerdos de asociación empresarial (BAA) proporcionados por el proveedor y su infraestructura de «Cumplimiento como Servicio». Es una protección legal, no técnica completa. | Directo. La institución es directamente responsable de implementar y auditar todas las medidas de seguridad técnicas, físicas y administrativas necesarias. |
| Bloqueo del proveedor | Alto. La integración profunda con la API propietaria del proveedor y el ecosistema de cumplimiento dificulta y encarece el cambio. | Ninguna. La institución posee la infraestructura y puede cambiar de modelo o marco según sea necesario. |
Sección 3: Gobernanza de datos en un ecosistema de IA globalizado
La decisión entre modelos de IA comerciales y de código abierto trasciende las consideraciones técnicas y económicas; es fundamentalmente una cuestión de soberanía. En una era donde los datos son un activo estratégico crucial, la capacidad de una nación o institución para controlar su destino digital es primordial.
3.1 Definición de la soberanía de los datos de salud en la era de la IA
Soberanía de los datos de salud se refiere al derecho que considero fundamental de las personas, comunidades y naciones para gestionar sus propios datos de salud. Esta gobernanza abarca todo el ciclo de vida de los datos, incluyendo su recopilación, almacenamiento, acceso, procesamiento y utilización, todo ello de conformidad con sus propias leyes, políticas y valores éticos. Se trata de un concepto complejo y multifacético que entrelaza el principio legal de la jurisdicción nacional sobre los datos con el principio ético de la autonomía del paciente y el interés colectivo en proteger la información de salud comunitaria.
Desde una perspectiva académica, la soberanía de los datos de salud no es un concepto estático ni simplel. Se entiende como una «autoridad distribuida y dependiente del contexto» que debe abordar críticamente las asimetrías de poder subyacentes y los sistemas sociotécnicos del ecosistema sanitario moderno. No se trata solo de control legal, sino de lograr la llamada —justicia de datos—que no es mas que garantizar que los beneficios derivados de las innovaciones basadas en datos se distribuyan equitativamente y que se respeten los derechos y valores de todas las poblaciones por igual. Exige entonces que dichos datos se recopilen, interpreten y utilicen de forma precisa, respetuosa y que sirva a los intereses de la propia comunidad, evitando una forma moderna de «colonialismo de datos» donde sus datos se explotan sin consentimiento ni beneficio.
El principio de soberanía de datos es crucial en la era de la IA, ya que estos modelos dependen fundamentalmente del acceso a vastos conjuntos de datos de alta calidad para su entrenamiento y funcionamiento. Por lo tanto, la gobernanza de los datos que impulsa la IA es fundamental para el desarrollo de sistemas de inteligencia artificial seguros, fiables y equitativos. Sin una afirmación firme de la soberanía de datos, las naciones y sus instituciones de salud corren el riesgo de ceder el control de su información de salud más sensible a un pequeño número de entidades comerciales extranjeras, lo que crea un estado de dependencia digital y socava su capacidad para proteger a sus ciudadanos.
3.2 Localización de datos: una solución necesaria pero insuficiente
En respuesta a las preocupaciones sobre la soberanía de los datos, muchos gobiernos han recurrido a localizar sus datos dentro sus fronteras como su principal herramienta política. La localización de datos se refiere al requisito legal de que los datos generados dentro de las fronteras de un país se almacenen y procesen físicamente dentro de esa misma jurisdicción, con sujeción a las leyes y regulaciones nacionales.
En el contexto de la atención médica, la localización de datos es un mecanismo clave para garantizar el cumplimiento de las leyes nacionales de privacidad, como la HIPAA en Estados Unidos o el RGPD en Europa. Al exigir que los datos confidenciales de los pacientes permanezcan en el país, los gobiernos buscan mejorar la protección de la privacidad y garantizar su capacidad legal para ejercer su autoridad. Además, el almacenamiento local de datos puede ofrecer beneficios operativos, como la reducción de los tiempos de recuperación de datos y la mejora de la eficiencia de los servicios de atención médica.
Sin embargo, aunque la localización de datos suele considerarse una solución sencilla, para lograr la verdadera soberanía, presenta una serie de desafíos importantes que pueden socavar sus beneficios previstos:
- Altos costos operativos:Establecer y mantener centros de datos locales requiere una inversión sustancial y a menudo duplicada en infraestructura física, lo que puede resultar prohibitivamente costoso para muchas organizaciones y países.
- Una barrera para la innovación:La principal desventaja de la localización estricta de datos es su potencial para frenar la innovación. Al restringir los flujos transfronterizos de datos, estas políticas pueden provocar la fragmentación de los conjuntos de datos globales. Esto es especialmente perjudicial para la investigación médica y el desarrollo de la IA, que prosperan gracias al acceso a conjuntos de datos grandes y diversos. Una encuesta realizada en 2022 a profesionales biofarmacéuticos reveló que más del 75 % creía que las normas de localización de datos retrasan activamente el descubrimiento de nuevos tratamientos médicos.
- Reducción de la representatividad de los datos y aumento del sesgo:Cuando los investigadores se limitan a utilizar únicamente datos locales, los conjuntos de datos pierden representatividad de la población global. Esto puede llevar al desarrollo de modelos de IA sesgados y con bajo rendimiento al aplicarse a diferentes grupos étnicos o demográficos. Casi dos tercios de los profesionales encuestados consideraron que las exigencias de localización reducen la representatividad de los datos recopilados en estudios clínicos, lo que puede exacerbar las desigualdades en salud.
La cuestión central es que la verdadera soberanía va más allá de la simple ubicación física de los datos; se trata de mantener un control significativo sobre cómo se utilizan. Una estrategia basada exclusivamente en la localización no aborda lo que ocurre con los datos dentro la frontera nacional. Si esos datos aún son procesados por un sistema de inteligencia artificial opaco y de «caja negra» controlado desde el extranjero, entonces no se ha alcanzado la soberanía genuina.
3.3 El camino del código abierto hacia la soberanía digital y de salud
Una estrategia centrada en modelos de código abierto autoalojados ofrece una vía más eficaz para lograr la soberanía de los datos de salud. Este enfoque permite a las naciones e instituciones conciliar la necesidad de control local con los beneficios de la innovación global.
Al implementar un LLM de código abierto en una infraestructura local, una institución de salud puede satisfacer los requisitos de localización de datos, manteniendo todos los datos de los pacientes físicamente dentro de su jurisdicción. Simultáneamente, puede aprovechar el ecosistema global de innovación de código abierto, utilizando, modificando e incluso contribuyendo a modelos de IA de vanguardia que una comunidad global está desarrollando y mejorando. Este enfoque separa la ubicación física de los datos del origen intelectual de las herramientas utilizadas para procesarlos, superando así la principal desventaja de las políticas tradicionales de localización de datos.
Esta estrategia proporciona un mayor nivel de soberanía. Otorga a la institución control no solo sobre los datos en sí, sino también sobre el software y los algoritmos que los procesan. Esta transparencia y control son imposibles con sistemas propietarios y son esenciales para construir una infraestructura de salud digital fiable y autónoma.
Sección 4: Recomendaciones y perspectiva estratégica
Tabla 2: Marco de decisión estratégica para la adopción de LLM en el ámbito sanitario
| Criterio de decisión | Caso de uso de bajo riesgo/no sensible (p. ej., educación médica general, tareas administrativas no relacionadas con datos privados de salud) | Caso de uso de alto riesgo/sensible (p. ej., apoyo a la toma de decisiones clínicas, análisis de la historia clínica electrónica, chatbots de atención al paciente) |
| Tipo de modelo recomendado | API propietaria (OBP) o de código abierto | Muy recomendable:Código abierto alojado en la nube (FTP) autoalojado o soberana |
| Justificación primaria | Velocidad de implementación y menor costo inicial para tareas no críticas donde la sensibilidad de los datos es mínima. | El control absoluto de los datos, la transparencia y la eliminación de los riesgos para la privacidad de terceros son primordiales. |
| Consideración clave sobre la privacidad | Asegúrese de que nunca se ingrese información médica protegida (datos privados de salud) ni datos organizacionales confidenciales en el sistema. Alto riesgo de cambios en las políticas. | Los datos deben permanecer dentro del perímetro seguro de la institución. Se requiere auditabilidad completa del sistema. |
| Modelo económico | Pago por uso (por token). Económico para volúmenes bajos. | Alta inversión inicial (CapEx), pero costos operativos (OpEx) bajos y predecibles. Económico para grandes volúmenes. |
| Requisito de cumplimiento | Bajo. Los acuerdos generales de usuario son suficientes. | Alto. Debe cumplir con todas las salvaguardias técnicas y administrativas de la HIPAA. El BAA por sí solo no es suficiente; el control técnico es clave. |
| Impacto de la soberanía | Baja. Dependencia estratégica mínima para funciones no esenciales. | Alto. Desarrolla la autonomía institucional y nacional sobre la infraestructura y los datos de salud críticos. |
4.1 Para instituciones de salud: un marco de decisión basado en riesgos para la adopción de LLM
Las instituciones de salud deben superar una visión monolítica de la IA y adoptar un marco matizado y basado en el riesgo para la implementación de LLM. No todas las aplicaciones conllevan el mismo nivel de riesgo, y la elección de la tecnología debe reflejarlo.
- Realizar una evaluación de riesgos específica para cada caso de uso:Antes de adoptar cualquier LLM, las instituciones deben categorizar la aplicación prevista en función de la sensibilidad de los datos.
- Para aplicaciones de bajo riesgo y no sensibles que no involucran datos privados de salud (por ejemplo, resumir investigación médica pública, generar contenido educativo genérico), el uso de una API comercial puede ser una solución aceptable y rentable.
- Para aplicaciones sensibles y de alto riesgo En las aplicaciones que implican el procesamiento de información médica protegida (por ejemplo, apoyo a la toma de decisiones clínicas, análisis de datos de historiales clínicos electrónicos, chatbots de diagnóstico para pacientes), los riesgos de privacidad y soberanía que presentan las API comerciales son probablemente inaceptables. Para estas funciones esenciales, la institución debería priorizar firmemente un modelo de código abierto alojado en la nube propia o soberana.
- Adopte una postura de «Confiar pero verificar» con los proveedores:Si considera un proveedor comercial, no se conforme con sus políticas de privacidad ni con sus afirmaciones de marketing. Exija un BAA, pero comprenda sus limitaciones. Realice una rigurosa diligencia debida sobre sus controles de seguridad técnica, políticas de retención de datos y la estabilidad de su gobierno corporativo. El «modelo de amenaza viva» requiere una monitorización continua, no una verificación de cumplimiento única.
- Invertir gradualmente en capacidad de código abierto:Incluso si un centro de datos local a gran escala no es viable, las instituciones deberían comenzar a desarrollar capacidad interna con herramientas de código abierto. Esto podría comenzar con modelos más pequeños y eficientes para tareas específicas, ejecutados en hardware de bajo costo. Esto genera experiencia interna esencial (LLMOps) y allana el camino para una mayor autonomía tecnológica en el futuro.
- Priorizar los sistemas con médicos en el circuito:Independientemente del modelo utilizado, la IA debe implementarse como un «copiloto» para complementar, y no reemplazar, el juicio clínico humano. Todos los resultados generados por IA para uso clínico deben ser revisados y validados por un profesional sanitario cualificado para garantizar la seguridad del paciente y mitigar el riesgo de alucinaciones o errores del modelo.
4.2 Construir un ecosistema de IA soberano y colaborativo en el hospital
Los gobiernos desempeñan un papel fundamental en la creación de un entorno donde los beneficios de la IA se materialicen sin sacrificar la soberanía ni los derechos ciudadanos. Un enfoque pasivo conducirá a la dependencia digital y a una mayor desigualdad.
- Desarrollar y armonizar marcos de gobernanza de datos:El panorama regulatorio fragmentado actual constituye un obstáculo importante para la innovación. Los gobiernos, a través de organismos regionales, deben colaborar para desarrollar regulaciones de gobernanza de datos modernas, claras y armonizadas. Estos marcos deben abordar específicamente las complejidades de los datos de salud y la IA, equilibrando la necesidad de una sólida protección de la privacidad con la necesidad de fomentar la innovación.
- Promover la inversión en infraestructura fundamental: Abordar los profundos déficits de infraestructura de la región es fundamental para el éxito de cualquier estrategia de IA. Esto requiere inversiones públicas y público-privadas específicas para ampliar el acceso a internet de alta velocidad (especialmente en zonas rurales), construir centros de datos nacionales y regionales, y adquirir recursos informáticos compartidos de alto rendimiento.
- Fomentar el intercambio de datos y modelos regionales:Para superar el problema de los conjuntos de datos pequeños y no representativos, los gobiernos deberían apoyar la creación de espacios regionales de datos de salud seguros y federados. Esto permitiría a investigadores y desarrolladores entrenar modelos de IA más robustos y equitativos con datos diversos de Latinoamérica sin comprometer la privacidad de los datos de ningún país. De igual manera, sería muy beneficioso colaborar para perfeccionar y mantener modelos de aprendizaje profundo (LLM) de código abierto para los idiomas y los desafíos de salud específicos de la región.
- Haga del capital humano una prioridad estratégica:El éxito a largo plazo de una estrategia soberana de IA depende del talento local. Los gobiernos deben invertir fuertemente en educación, creando programas públicos de capacitación en IA e integrando la ciencia de datos y la ética de la IA en los planes de estudio universitarios, en particular en las facultades de medicina e ingeniería.
4.3 Fomento de la innovación ética y transparente
La comunidad de investigadores, empresarios y desarrolladores tiene la responsabilidad de orientar la adopción de la IA en una dirección que sea a la vez innovadora y ética.
- Defender la transparencia:Los desarrolladores deben priorizar el uso de modelos de código abierto transparentes y auditables siempre que sea posible. Al utilizar modelos propietarios, deben ser transparentes con sus clientes y usuarios finales sobre los posibles riesgos y las limitaciones de la tecnología.
- Centrarse en las necesidades locales:Los innovadores deben centrarse en resolver los desafíos de salud específicos y urgentes de la región latinoamericana, en lugar de simplemente importar soluciones diseñadas para países de altos ingresos. Esto incluye el desarrollo de herramientas que funcionen en entornos de baja conectividad y se adapten a los perfiles demográficos y epidemiológicos únicos de la región.
- Participar en el diálogo público y sobre políticas:La comunidad de tecnología de salud debe participar activamente en el debate público y en los procesos de formulación de políticas. Al compartir su experiencia, puede ayudar a educar a los responsables políticos y al público sobre los riesgos y beneficios reales de la IA, contribuyendo así al desarrollo de una gobernanza sensata y eficaz.
Conclusión
La llegada de los grandes modelos del lenguaje representa un momento crucial para la atención médica a nivel mundial, y en particular para Latinoamérica. Esta tecnología ofrece una promesa tentadora: superar las brechas de infraestructura, mejorar las capacidades de diagnóstico y democratizar el acceso al conocimiento médico en una región que enfrenta importantes desafíos en su sistema de salud. Sin embargo, esta promesa se ve ensombrecida por un profundo peligro. Los modelos comerciales dominantes de IA, ofrecidos como soluciones convenientes, potentes y fáciles de implementar, funcionan como «cajas negras» opacas que exigen un pacto fáustico: a cambio de utilidad, las instituciones deben ceder el control sobre los datos más sensibles de sus pacientes, exponiéndolos a un panorama complejo y cambiante de riesgos para la privacidad y creando un estado de dependencia estratégica a largo plazo.
Este informe ha demostrado que la alternativa —una vía centrada en modelos autoalojados de código abierto— ofrece una solución clara a la crisis de soberanía de datos. Permite a las instituciones de salud mantener el control absoluto sobre los datos de los pacientes, beneficiarse de la transparencia algorítmica y construir un futuro tecnológico sin dependencia de proveedores. La reciente y rápida convergencia del rendimiento de los modelos de código abierto con el de sus homólogos propietarios hace que esta vía sea más viable y atractiva que nunca.
Sin embargo, los desafíos para esta vía soberana, especialmente en América Latina, son inmensos. Los altos costos de infraestructura, la complejidad operativa de la gestión de estos sistemas y, lo más crítico, el grave déficit de capital humano especializado, crean barreras formidables. Abogar simplemente por una transición generalizada e inmediata hacia la IA de código abierto autoalojada equivaldría a ignorar la cruda realidad.
Por lo tanto, el camino a seguir debe ser estratégico, gradual y colaborativo. Requiere un enfoque matizado y basado en el riesgo dentro de las instituciones de salud, un esfuerzo concertado de los responsables políticos para construir una infraestructura fundacional y una gobernanza armonizada, y un compromiso de la comunidad tecnológica para innovar responsablemente. Para América Latina, el camino hacia el aprovechamiento del poder de la IA en la atención médica será una maratón, no una carrera de velocidad. Es un camino que debe recorrerse con una comprensión clara de las desventajas, un compromiso firme con los derechos de los pacientes y un enfoque inquebrantable en el objetivo final: construir un futuro de salud digital más equitativo, eficiente y soberano para todos sus ciudadanos.
Este artículo fue escrito con ayuda de IA gemini, declarando que fue leído, curado y procesado por completo por el autor.
Fuentes citadas
- Safi, S. M. R., Safi, S. M. R., & Billah, M. M. (2024). Benefits and risks of AI in health care: Narrative review. Cureus, 16(9), e68691. https://doi.org/10.7759/cureus.68691
- UniqueMinds.AI. (n.d.). The Anthropic policy reversal: A case study in AI governance. Retrieved June 14, 2025, from https://uniqueminds.ai/the-anthropic-policy-reversal-a-case-study-in-ai-governance/
- Dennstädt, F., Hastings, J., Putora, P. M., Schmerder, M., & Cihoric, N. (2025, March). Implementing large language models in healthcare while balancing control, collaboration, costs and security. npj Digital Medicine. https://www.researchgate.net/publication/389649560_Implementing_large_language_models_in_healthcare_while_balancing_control_collaboration_costs_and_security
- Latitude. (n.d.). Open-source vs proprietary LLMs: Cost breakdown. Ghost. Retrieved June 14, 2025, from https://latitude-blog.ghost.io/blog/open-source-vs-proprietary-llms-cost-breakdown/
- EnterpriseLLMguy. (2024, May 29). The real cost of hosting an LLM. [Online forum post]. Reddit. https://www.reddit.com/r/LocalLLaMA/comments/1jzeo0l/the_real_cost_of_hosting_an_llm/
- Gilbert, S., et al. (2024). Current safeguards, risk mitigation, and transparency measures of large language models against the generation of health disinformation: Repeated cross sectional analysis. BMJ, 384, e078538. https://doi.org/10.1136/bmj-2023-078538
- OpenAI. (n.d.). Enterprise privacy at OpenAI. Retrieved June 14, 2025, from https://openai.com/enterprise-privacy/
- OpenAI. (n.d.). Privacy policy. Retrieved June 14, 2025, from https://openai.com/policies/row-privacy-policy/
- OpenAI. (n.d.). OpenAI privacy center. Retrieved June 14, 2025, from https://privacy.openai.com/
- Prictor, M., & Lewis, J. (2024). Open AI meets open notes: Surveillance capitalism, patient privacy and online record access. Journal of Medical Ethics, 50(2), 84–85. https://doi.org/10.1136/jme-2023-109433
- Microsoft. (2024, March 28). Protecting the data of our commercial and public sector customers in the era of generative AI. On the Issues. https://blogs.microsoft.com/on-the-issues/2024/03/28/data-protection-responsible-ai-azure-copilot/
- BASOFA. (n.d.). Azure OpenAI service: Security, compliance, & privacy. Retrieved June 14, 2025, from https://www.basofa.com/azure-openai-service-data-security-and-privacy/
- Anthropic. (2025, May 1). Updates to our privacy policy. https://privacy.anthropic.com/en/articles/10301952-updates-to-our-privacy-policy
- Sceberras, J. P., et al. (2024). Are LLM-based methods good enough for detecting unfair terms of service? ResearchGate. https://www.researchgate.net/publication/383701857_Are_LLM-based_methods_good_enough_for_detecting_unfair_terms_of_service
- OpenAI. (n.d.). Security & privacy. Retrieved June 14, 2025, from https://openai.com/security-and-privacy/
- Hathr AI. (n.d.). HIPAA compliant LLM for healthcare. Retrieved June 14, 2025, from https://hathr.ai/hipaa-compliant-llm-for-healthcare/
- Busch, F., Hoffmann, L., Rueger, C., van Dijk, E. H. C., Kader, R., Ortiz-Prado, E., Makowski, M. R., Saba, L., Hadamitzky, M., & Kather, J. N. (2025). Current applications and challenges in large language models for patient care: a systematic review. npj Digital Medicine. https://pmc.ncbi.nlm.nih.gov/articles/PMC11751060/
- Buckley TA, Crowe B, Abdulnour RE, Rodman A, Manrai AK. Comparison of Frontier Open-Source and Proprietary Large Language Models for Complex Diagnoses. JAMA Health Forum. 2025;6(3):e250040. doi:10.1001/jamahealthforum.2025.0040
- European Parliament. (2021). Challenges and limits of an open source approach to artificial intelligence. https://www.europarl.europa.eu/RegData/etudes/STUD/2021/662908/IPOL_STU(2021)662908_EN.pdf
- Bioengineer.org. (2025, March 15). Open-source AI rivals leading proprietary models in tackling complex medical cases. https://bioengineer.org/open-source-ai-rivals-leading-proprietary-models-in-tackling-com
Smith, J., et al. (2024). Leveraging open-source large language models for data augmentation in hospital staff surveys: Mixed methods study. JMIR Medical Education, 10, e51433. https://mededu.jmir.org/2024/1/e51433/
