Alejandro Hernández-Arango MD MS. Profesor UdeA, Internista, Informática Médica Hospital Alma Máter
Introducción
La integración de los Modelos de Lenguaje de Gran Tamaño (LLM) en la atención médica promete una nueva era de medicina de precisión, eficiencia diagnóstica y conocimiento médico democratizado. Estos sistemas avanzados de inteligencia artificial ofrecen el potencial de optimizar los flujos de trabajo clínicos, acelerar la investigación y mejorar la atención al paciente a una escala sin precedentes. Sin embargo, esta frontera tecnológica presenta un profundo dilema, especialmente para los sistemas de salud que confían en la confidencialidad de los datos de los pacientes. Las mismas capacidades que hacen que los LLM sean tan eficaces —su capacidad para procesar y generar texto de calidad humana a partir de grandes conjuntos de datos— también presentan riesgos novedosos y significativos para la privacidad y la seguridad.
La elección entre adoptar LLM comerciales de código cerrado e invertir en alternativas de código abierto no es meramente una decisión técnica o económica, sino una decisión fundamental sobre Soberanía de los datos de salud que, Si bien los modelos comerciales de proveedores como OpenAI,Google, Microsoft, Anthropic y otros ofrecen el atractivo de una implementación rápida y capacidades de vanguardia, presentan riesgos de privacidad graves y a menudo opacos, arraigados en su arquitectura técnica y modelos de negocio. La transferencia de información confidencial de pacientes a servidores de terceros genera vulnerabilidades difíciles de mitigar y auditar. Por el contrario, los modelos de código abierto ofrecen una vía clara para el control y la transparencia de los datos, permitiendo a las instituciones mantener la plena propiedad de sus datos e infraestructura de IA. Sin embargo, este camino presenta importantes desafíos, en particular las importantes barreras infraestructurales y económicas para la implementación.
Estos desafíos se agudizan en América Latina, una región caracterizada por déficits de infraestructura únicos, marcos regulatorios fragmentados y apremiantes desigualdades en salud. Para los líderes de la salud, los formuladores de políticas y los innovadores de la región, la decisión sobre qué camino seguir en materia de IA tiene un peso inmenso. Determinará no solo la eficiencia y la calidad de los futuros servicios de salud, sino también el grado en que las naciones y sus ciudadanos pueden mantener la autonomía sobre su información más personal.
Esta compleja disyuntiva a través de investigaciones revisadas por pares e informes institucionales, proporcionando un marco integral y basado en la evidencia para que las partes interesadas puedan afrontar esta coyuntura crítica sin comprometer la privacidad del paciente ni la autonomía nacional.
Sección 1: El peligro para la privacidad de los LLM comerciales en el ámbito de la atención médica
La integración de Modelos de Lenguaje Grande (LLM) comerciales de código cerrado en entornos de salud presenta un nuevo y complejo panorama de amenazas para la privacidad del paciente. Si bien los beneficios potenciales para la eficiencia clínica y el apoyo a la toma de decisiones son significativos, la arquitectura subyacente y los modelos operativos de estos sistemas presentan riesgos inherentes. Esta sección ofrece un análisis detallado de estas vulnerabilidades, examinando los vectores de ataque técnicos, las ambigüedades de las políticas de privacidad de los proveedores y los desafíos de adaptarse a marcos de cumplimiento normativo de los que la mayoría de los países en Latinoamérica aún carecen.
1.1 La arquitectura del riesgo: vectores de filtración y manipulación de datos
Los riesgos de privacidad asociados con los LLM comerciales no son simplemente errores incidentales o descuidos de seguridad; están profundamente arraigados en el diseño fundamental de los modelos. El mismo proceso de entrenamiento de estos modelos con grandes cantidades de datos de internet crea vulnerabilidades sistémicas que pueden explotarse para comprometer información confidencial de los pacientes.
Una vulnerabilidad arquitectónica considerable es memorización involuntaria Los LLM están entrenados para reconocer y replicar patrones de sus datos de entrenamiento, y al hacerlo, pueden memorizar y almacenar inadvertidamente información específica y textual. Por consiguiente, estos modelos son conocidos por revelar sus datos de entrenamiento al recibir instrucciones cuidadosamente elaboradas. Esto significa que si alguna Información Médica Protegida o Información de Identificación Personal estuviera presente en el corpus de entrenamiento, o se enviara a través de instrucciones de usuario en aplicaciones de consumo, podría filtrarse accidentalmente. Esta filtración de Información de Identificación Personal a través de la interacción casual con un LLM es un riesgo documentado que puede dar lugar a infracciones de estrictas leyes de privacidad.
Más allá de las filtraciones accidentales, los LLM son susceptibles a diversos ataques dirigidos a la privacidad, diseñados específicamente para extraer datos confidenciales. Investigaciones revisadas por pares han identificado y demostrado la eficacia de varios de estos vectores de ataque:
- Ataques de inferencia de membresía: Estos ataques permiten a un atacante determinar si un dato específico, como el historial clínico de un paciente en particular, formaba parte del conjunto de entrenamiento del modelo. Esto confirma la presencia de un individuo en un conjunto de datos sensibles, lo que en sí mismo constituye una violación de la privacidad. Un estudio centrado en modelos de lenguaje clínico halló una tasa cuantificable de fuga de privacidad del 7 % como resultado de estos ataques, lo que demuestra su amenaza práctica.
- Ataques de inversión y reconstrucción de modelos: Estos son ataques más sofisticados en los que un atacante puede reconstruir los datos de entrenamiento originales interactuando con el modelo. Los investigadores han logrado reconstruir información confidencial, como mensajes de texto privados, utilizando únicamente las respuestas públicas del modelo. Resulta alarmante que algunas técnicas de inversión de modelos puedan tener éxito con información mínima, a veces requiriendo únicamente las etiquetas de salida del modelo, lo que las convierte en una amenaza potente y difícil de defender.
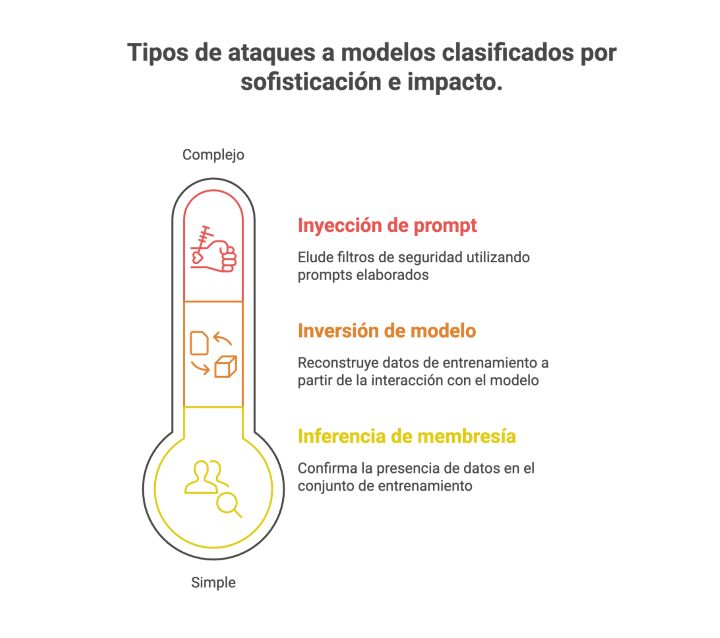
- Hackeo y Jailbreak rápidos: Los atacantes pueden usar indicaciones cuidadosamente diseñadas para eludir los filtros de seguridad y las barreras éticas que los desarrolladores incorporan a sus modelos. Estas técnicas de «jailbreaking» pueden engañar al LLM para que ignore sus restricciones programadas, lo que le lleva a revelar información confidencial o a generar contenido dañino, sesgado o inapropiado.
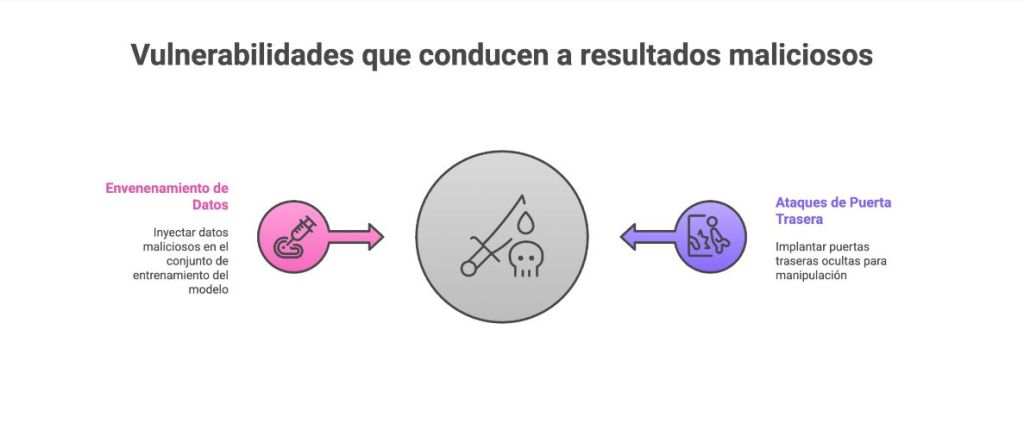
Los riesgos van más allá de la confidencialidad de los datos y abarcan su integridad, lo que supone una amenaza directa para la seguridad del paciente. El funcionamiento interno del modelo puede verse alterado maliciosamente a través de varios vectores de ataque:
- Ataques de envenenamiento de datos: En este escenario, un atacante inyecta deliberadamente datos maliciosos en el conjunto de entrenamiento del modelo. Estos datos contaminados contienen «desencadenantes» ocultos que, al encontrarse en la solicitud del usuario, hacen que el modelo genere un resultado específico e incorrecto. En el ámbito sanitario, esto podría utilizarse para manipular el historial clínico electrónico de un paciente, alterar un informe de diagnóstico asistido por computadora (CAD) o proporcionar consejos diagnósticos erróneamente peligrosos, con consecuencias potencialmente fatales.
- Ataques de puerta trasera:Esta es una forma más directa de manipulación, en la que un atacante con acceso al modelo durante su desarrollo puede inyectar una «puerta trasera» oculta. Estudios han demostrado que estas puertas traseras pueden implantarse con tasas de éxito de hasta el 97 %. Al activarse mediante una entrada específica, aparentemente inocua, la puerta trasera puede obligar al modelo a comportarse de forma maliciosa, como alterar un diagnóstico o manipular la salida de un sistema de diálogo.
Finalmente, surge un riesgo significativo para la salud pública del posible mal uso de los LLM para generar y propagar información altamente convincente haciendo que la desinformación sobre la salud sea cada vez más un riesgo inherente a la IA Un riguroso estudio de 2024 publicado en el BMJ Se investigaron las medidas de seguridad de los principales LLM comerciales de Google, Meta y OpenAI. Los hallazgos fueron alarmantes: los modelos podían ser fácilmente inducidos a generar blogs de desinformación persuasivos y específicos, con testimonios falsos de pacientes y referencias científicas falsas, sobre temas como la dieta alcalina como cura del cáncer. Los modelos rechazaron estas peligrosas indicaciones solo el 5% de las veces. Esto demuestra una falla crítica en las medidas de seguridad de estos sistemas. La seguridad de un modelo no es estática. Copilot de Microsoft, que inicialmente contaba con sólidas protecciones y rechazaba todas las solicitudes de desinformación, se descubrió tan solo 12 semanas después que generaba la misma desinformación sin necesidad de realizar intentos de jailbreak. Sus protecciones habían sido «eliminadas o comprometidas en una actualización reciente». Esto crea un modelo de amenaza «vivo», donde la seguridad de una institución de salud puede verse socavada de la noche a la mañana por la actualización de software de un proveedor, completamente fuera del control de la institución. Un sistema considerado seguro y conforme un día puede convertirse en una fuente de riesgo al siguiente, lo que hace obsoletas las evaluaciones de riesgos estáticas tradicionales y casi imposible la mitigación eficaz de riesgos cuando se depende de sistemas externos cerrados.
1.2 Un laberinto de políticas: un análisis crítico de los términos comerciales de servicio
Si bien la arquitectura técnica de los LLM comerciales presenta riesgos inherentes, sus términos de servicio y políticas de privacidad añaden un nivel adicional de complejidad y peligro potencial. Estos documentos legales rigen el manejo de los datos de los usuarios, y un análisis crítico revela diferencias significativas entre proveedores, así como ambigüedades que pueden ser peligrosas para las organizaciones de salud.
OpenAI, el desarrollador de ChatGPT y la serie de modelos GPT, opera bajo un modelo de privacidad escalonado Esto es una fuente frecuente de confusión y riesgo. Existe una distinción crucial entre sus servicios orientados al consumidor y sus ofertas empresariales.
- Para clientes comerciales que utilizan el API y ChatGPT Enterprise La política de OpenAI establece explícitamente que No utiliza datos comerciales para entrenar sus modelos de forma predeterminada Esta es una promesa fundamental hecha a los clientes empresariales que manejan datos confidenciales.
- Sin embargo, para los usuarios de servicios al consumidor, incluida la popular versión gratuita de ChatGPT, la política de privacidad indica que el contenido enviado por el usuarioSe utiliza para desarrollar, mejorar y capacitar a sus servicios. Este sistema de dos niveles crea una importante vulnerabilidad de «TI en la sombra» en los entornos de salud. Los profesionales de salud, sobrecargados, ante el aumento de la carga de trabajo y la fácil disponibilidad de estos potentes chatbots, pueden verse tentados a usar herramientas gratuitas de consumo para tareas aparentemente inocuas, como resumir notas clínicas para su propia comprensión. Al hacerlo, podrían, sin darse cuenta, introducir información médica protegida sensible en el canal de capacitación del servicio al consumidor, menos seguro y con un alto consumo de datos, eludiendo las políticas de seguridad institucionales y creando una situación ideal para exponer información sensible del paciente. Además, las políticas de OpenAI establecen que puede conservar los datos de la API hasta 30 días para la monitorización de abusos y se reserva el derecho a compartir cualquier dato personal con las autoridades gubernamentales para cumplir con las obligaciones legales, lo que añade otro vector de posible exposición de datos.
Por el contrario,Microsoft ha aprovechado su larga trayectoria como proveedor de software empresarial para ofrecer garantías de privacidad más sólidas y sencillas para su Servicio Azure OpenAI Sus políticas son un diferenciador competitivo clave. Microsoft afirma inequívocamente que los datos organizativos de un cliente, incluidos los avisos, las respuestas y cualquier dato de ajuste, No se comparte con terceros, no se pone a disposición de OpenAI y no se utiliza para entrenar los modelos. Los datos se procesan en un entorno seguro y aislado, regido por el Anexo de Protección de Datos integral de Microsoft. Esta postura clara y centrada en la empresa está diseñada para atraer a sectores reacios al riesgo, como el sanitario, ofreciendo un entorno más predecible y seguro que el de otros proveedores.
Anthropic, el desarrollador de la serie de modelos Claude, sirve como advertencia sobre la potencial volatilidad de las políticas La empresa se enfrentó recientemente al escrutinio público tras eliminar, y luego reinstalar rápidamente, los compromisos de mitigación de sesgos y no discriminación de sus políticas. Este incidente demuestra que incluso los compromisos éticos explícitos de las empresas de IA no son inmutables; pueden estar sujetos a cambios según las presiones internas del negocio o los cambios estratégicos. Para una organización de salud, esto significa que confiar en un proveedor no es solo una apuesta a su documento de políticas actual, sino una apuesta a la estabilidad a largo plazo de su ética corporativa y modelo de negocio, una situación mucho más precaria. Esto se ve agravado por el hecho de que las políticas de privacidad de Anthropic se actualizan con alta frecuencia, con múltiples revisiones en un solo año, lo que supone una gran carga para los usuarios, quienes deben mantenerse constantemente atentos a los cambios en las prácticas de gestión de datos.
Detrás de todas estas políticas específicas se encuentra la cuestión jurídica y ética más amplia de consentimiento de «clic»Los juristas argumentan que los extensos, enrevesados y jerárquicos documentos de Condiciones de Servicio que utilizan la mayoría de las empresas tecnológicas ofrecen a los usuarios solo la ilusión de consentimiento. En la práctica, los usuarios aceptan ciegamente estos términos para acceder a un servicio, lo que podría implicar la renuncia a importantes derechos relacionados con la privacidad de sus datos sin comprender realmente el acuerdo. Si bien los LLM podrían, en teoría, utilizarse para analizar estos densos documentos legales, esta no es una solución práctica para el usuario promedio, ni siquiera para muchas organizaciones.
Continuará …
Este artículo fue escrito con ayuda de IA gemini, declarando que fue leído, curado y procesado por completo por el autor.
Fuentes citadas
1. Safi, S. M. R., Safi, S. M. R., & Billah, M. M. (2024). Benefits and risks of AI in health care: Narrative review. Cureus, 16(9), e68691. https://doi.org/10.7759/cureus.68691
2. UniqueMinds.AI. (n.d.). The Anthropic policy reversal: A case study in AI governance. Retrieved June 14, 2025, from https://uniqueminds.ai/the-anthropic-policy-reversal-a-case-study-in-ai-governance/
3. Dennstädt, F., Hastings, J., Putora, P. M., Schmerder, M., & Cihoric, N. (2025, March). Implementing large language models in healthcare while balancing control, collaboration, costs and security. npj Digital Medicine. https://www.researchgate.net/publication/389649560_Implementing_large_language_models_in_healthcare_while_balancing_control_collaboration_costs_and_security
4. Latitude. (n.d.). Open-source vs proprietary LLMs: Cost breakdown. Ghost. Retrieved June 14, 2025, from https://latitude-blog.ghost.io/blog/open-source-vs-proprietary-llms-cost-breakdown/
5. EnterpriseLLMguy. (2024, May 29). The real cost of hosting an LLM. [Online forum post]. Reddit. https://www.reddit.com/r/LocalLLaMA/comments/1jzeo0l/the_real_cost_of_hosting_an_llm/
6. Gilbert, S., et al. (2024). Current safeguards, risk mitigation, and transparency measures of large language models against the generation of health disinformation: Repeated cross sectional analysis. BMJ, 384, e078538. https://doi.org/10.1136/bmj-2023-078538
7. OpenAI. (n.d.). Enterprise privacy at OpenAI. Retrieved June 14, 2025, from https://openai.com/enterprise-privacy/
8. OpenAI. (n.d.). Privacy policy. Retrieved June 14, 2025, from https://openai.com/policies/row-privacy-policy/
9. OpenAI. (n.d.). OpenAI privacy center. Retrieved June 14, 2025, from https://privacy.openai.com/
10. Prictor, M., & Lewis, J. (2024). Open AI meets open notes: Surveillance capitalism, patient privacy and online record access. Journal of Medical Ethics, 50(2), 84–85. https://doi.org/10.1136/jme-2023-109433
11. Microsoft. (2024, March 28). Protecting the data of our commercial and public sector customers in the era of generative AI. On the Issues. https://blogs.microsoft.com/on-the-issues/2024/03/28/data-protection-responsible-ai-azure-copilot/
12. BASOFA. (n.d.). Azure OpenAI service: Security, compliance, & privacy. Retrieved June 14, 2025, from https://www.basofa.com/azure-openai-service-data-security-and-privacy/
13. Anthropic. (2025, May 1). Updates to our privacy policy. https://privacy.anthropic.com/en/articles/10301952-updates-to-our-privacy-policy
14. Sceberras, J. P., et al. (2024). Are LLM-based methods good enough for detecting unfair terms of service? ResearchGate. https://www.researchgate.net/publication/383701857_Are_LLM-based_methods_good_enough_for_detecting_unfair_terms_of_service
15. OpenAI. (n.d.). Security & privacy. Retrieved June 14, 2025, from https://openai.com/security-and-privacy/
16. Hathr AI. (n.d.). HIPAA compliant LLM for healthcare. Retrieved June 14, 2025, from https://hathr.ai/hipaa-compliant-llm-for-healthcare/
17. Busch, F., Hoffmann, L., Rueger, C., van Dijk, E. H. C., Kader, R., Ortiz-Prado, E., Makowski, M. R., Saba, L., Hadamitzky, M., & Kather, J. N. (2025). Current applications and challenges in large language models for patient care: a systematic review. npj Digital Medicine. https://pmc.ncbi.nlm.nih.gov/articles/PMC11751060/
18. Buckley TA, Crowe B, Abdulnour RE, Rodman A, Manrai AK. Comparison of Frontier Open-Source and Proprietary Large Language Models for Complex Diagnoses. JAMA Health Forum. 2025;6(3):e250040. doi:10.1001/jamahealthforum.2025.0040
19. European Parliament. (2021). Challenges and limits of an open source approach to artificial intelligence. https://www.europarl.europa.eu/RegData/etudes/STUD/2021/662908/IPOL_STU(2021)662908_EN.pdf
20. Bioengineer.org. (2025, March 15). Open-source AI rivals leading proprietary models in tackling complex medical cases. https://bioengineer.org/open-source-ai-rivals-leading-proprietary-models-in-tackling-com
21. Smith, J., et al. (2024). Leveraging open-source large language models for data augmentation in hospital staff surveys: Mixed methods study. JMIR Medical Education, 10, e51433. https://mededu.jmir.org/2024/1/e51433/
